
富达资讯

全国统一免费咨询电话
400-123-4567
传真:+86-123-4567
手机:138-0000-0000
Q Q:1234567890
E_mail:admin@youweb.com
地址:广东省广州市天河区88号
前端性能优化有哪些实用的方法呢?
为什么要做性能优化?性能优化到底有多重要?网站的性能优化对于用户的留存率、转化率有很大的影响,所以对于前端开发来说性能优化能力也是重要的考察点。
性能优化的点非常的多,有的小伙伴觉得记起来非常的麻烦,所以这里主要梳理出一条线来帮助记忆。
可以将性能优化分为两个大的分类:
顾名思义加载时优化 主要解决的就是让一个网站加载过程更快,比如压缩文件大小、使用CDN加速等方式可以优化加载性能。检查加载性能的指标一般看:白屏时间和首屏时间:
将代码脚本放在 </head> 前面就能获取白屏时间:
<script>
new Date().getTime() - performance.timing.navigationStart
</script>
在window.onload事件中执行以下代码,可以获取首屏时间:
new Date().getTime() - performance.timing.navigationStart
运行时性能是指页面运行时的性能表现,而不是页面加载时的性能。可以通过chrome开发者工具中的 Performance 面板来分析页面的运行时性能。
接下来就从加载时性能和运行时性能两个方面来讨论网站优化具体应该怎么做。
我们知道浏览器如果输入的是一个网址,首先要交给DNS域名解析 -> 找到对应的IP地址 -> 然后进行TCP连接 -> 浏览器发送HTTP请求 -> 服务器接收请求 -> 服务器处理请求并返回HTTP报文 -> 以及浏览器接收并解析渲染页面。从这一过程中,其实就可以挖出优化点,缩短请求的时间,从而去加快网站的访问速度,提升性能。
这个过程中可以提升性能的优化的点:
从上面几个优化点出发,有以下几种实现性能优化的方式。
DNS 作为互联网的基础协议,其解析的速度似乎容易被网站优化人员忽视。现在大多数新浏览器已经针对DNS解析进行了优化,典型的一次DNS解析耗费20-120毫秒,减少DNS解析时间和次数是个很好的优化方式。
DNS Prefetching是具有此属性的域名不需要用户点击链接就在后台解析,而域名解析和内容载入是串行的网络操作,所以这个方式能减少用户的等待时间,提升用户体验。
浏览器对网站第一次的域名DNS解析查找流程依次为:
浏览器缓存 ->系统缓存 ->路由器缓存 ->ISP DNS缓存 ->递归搜索
DNS预解析的实现:
用meta信息来告知浏览器, 当前页面要做DNS预解析:
<meta http-equiv="x-dns-prefetch-control" content="on" />
在页面header中使用link标签来强制对DNS预解析:
<link rel="dns-prefetch" href="http://bdimg.share.baidu.com" />
注意:dns-prefetch需慎用,多页面重复DNS预解析会增加重复DNS查询次数。
HTTP2带来了非常大的加载优化,所以在做优化上首先就想到了用HTTP2代替HTTP1。
HTTP2相对于HTTP1有这些优点:
解析速度快
服务器解析 HTTP1.1 的请求时,必须不断地读入字节,直到遇到分隔符 CRLF 为止。而解析 HTTP2 的请求就不用这么麻烦,因为 HTTP2 是基于帧的协议,每个帧都有表示帧长度的字段。
多路复用
在 HTTP2 上,多个请求可以共用一个 TCP 连接,这称为多路复用。
当然HTTP1.1有一个可选的Pipelining技术,说的意思是当一个HTTP连接在等待接收响应时可以通过这个连接发送其他请求。听起来很棒,其实这里有一个坑,处理响应是按照顺序的,也就是后发的请求有可能被先发的阻塞住,也正因此很多浏览器默认是不开启Pipelining的。
HTTP1 的Pipelining技术会有阻塞的问题,HTTP/2的多路复用可以粗略的理解为非阻塞版的Pipelining。即可以同时通过一个HTTP连接发送多个请求,谁先响应就先处理谁,这样就充分的压榨了TCP这个全双工管道的性能。加载性能会是HTTP1的几倍,需要加载的资源越多越明显。当然多路复用是建立在加载的资源在同一域名下,不同域名神仙也复用不了。
首部压缩
HTTP2 提供了首部压缩功能。(这部分了解一下就行)
HTTP 1.1请求的大小变得越来越大,有时甚至会大于TCP窗口的初始大小,因为它们需要等待带着ACK的响应回来以后才能继续被发送。HTTP/2对消息头采用HPACK(专为http/2头部设计的压缩格式)进行压缩传输,能够节省消息头占用的网络的流量。而HTTP/1.x每次请求,都会携带大量冗余头信息,浪费了很多带宽资源。
服务器推送
服务端可以在发送页面HTML时主动推送其它资源,而不用等到浏览器解析到相应位置,发起请求再响应。
HTTP请求建立和释放需要时间。
HTTP请求从建立到关闭一共经过以下步骤:
这些步骤都是需要花费时间的,在网络情况差的情况下,花费的时间更长。如果页面的资源非常碎片化,每个HTTP请求只带回来几K甚至不到1K的数据(比如各种小图标)那性能是非常浪费的。
我们可以对html、css、js以及图片资源进行压缩处理,现在可以很方便的使用 webpack 实现文件的压缩:
提取公共代码
合并文件虽然能减少HTTP请求数量, 但是并不是文件合并越多越好,还可以考虑按需加载方式(后面第6点有讲到)。什么样的文件可以合并呢?可以提取项目中多次使用到的公共代码进行提取,打包成公共模块。
可以使用 webpack4 的 splitChunk 插件 cacheGroups 选项。
optimization: {
runtimeChunk: {
name: 'manifest' // 将 webpack 的 runtime 代码拆分为一个单独的 chunk。
},
splitChunks: {
cacheGroups: {
vendor: {
name: 'chunk-vendors',
test: /[\\\/]node_modules[\\\/]/,
priority: -10,
chunks: 'initial'
},
common: {
name: 'chunk-common',
minChunks: 2,
priority: -20,
chunks: 'initial',
reuseExistingChunk: true
}
},
}
},
因为字体图标或者SVG是矢量图,代码编写出来的,放大不会失真,而且渲染速度快。字体图标使用时就跟字体一样,可以设置属性,例如 font-size、color 等等,非常方便,还有一个优点是生成的文件特别小。
按需加载
在开发SPA项目时,项目中经常存在十几个甚至更多的路由页面, 如果将这些页面都打包进一个JS文件, 虽然减少了HTTP请求数量, 但是会导致文件比较大,同时加载了大量首页不需要的代码,有些得不偿失,这时候就可以使用按需加载, 将每个路由页面单独打包为一个文件,当然不仅仅是路由可以按需加载。
根据文件内容生成文件名,结合 import 动态引入组件实现按需加载:
通过配置 output 的 filename 属性可以实现这个需求。filename 属性的值选项中有一个 [contenthash],它将根据文件内容创建出唯一 hash。当文件内容发生变化时,[contenthash] 也会发生变化。
output: {
filename: '[name].[contenthash].js',
chunkFilename: '[name].[contenthash].js',
path: path.resolve(__dirname, 'https://www.zhihu.com/dist'),
},
减少冗余代码
一方面避免不必要的转义:babel-loader用 include 或 exclude 来帮我们避免不必要的转译,不转译node_moudules中的js文件,其次在缓存当前转译的js文件,设置loader: 'babel-loader?cacheDirectory=true'
其次减少ES6 转为 ES5 的冗余代码:Babel 转化后的代码想要实现和原来代码一样的功能需要借助一些帮助函数,比如:
class Person{}
会被转换为:
"use strict";
function _classCallCheck(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
}
}
var Person = function Person() {
_classCallCheck(this, Person);
};
这里 _classCallCheck 就是一个 helper 函数,如果在很多文件里都声明了类,那么就会产生很多个这样的 helper 函数。
这里的 @babel/runtime 包就声明了所有需要用到的帮助函数,而 @babel/plugin-transform-runtime 的作用就是将所有需要 helper 函数的文件,从 @babel/runtime包 引进来:
"use strict";
var _classCallCheck2 = require("@babel/runtime/helpers/classCallCheck");
var _classCallCheck3 = _interopRequireDefault(_classCallCheck2);
function _interopRequireDefault(obj) {
return obj && obj.__esModule ? obj : { default: obj };
}
var Person = function Person() {
(0, _classCallCheck3.default)(this, Person);
};
这里就没有再编译出 helper 函数 classCallCheck 了,而是直接引用了@babel/runtime 中的 helpers/classCallCheck。
npm i -D @babel/plugin-transform-runtime @babel/runtime使用 在 .babelrc 文件中
"plugins": [
"@babel/plugin-transform-runtime"
]
客户端渲染: 获取 HTML 文件,根据需要下载 JavaScript 文件,运行文件,生成 DOM,再渲染。
服务端渲染:服务端返回 HTML 文件,客户端只需解析 HTML。
优点:首屏渲染快,SEO 好。缺点:配置麻烦,增加了服务器的计算压力。
尽量将 CSS 放在文件头部,JavaScript 文件放在底部
所有放在 head 标签里的 CSS 和 JS 文件都会堵塞渲染。如果这些 CSS 和 JS 需要加载和解析很久的话,那么页面就空白了。所以 JS 文件要放在底部,等 HTML 解析完了再加载 JS 文件。
那为什么 CSS 文件还要放在头部呢?
因为先加载 HTML 再加载 CSS,会让用户第一时间看到的页面是没有样式的、“丑陋”的,为了避免这种情况发生,就要将 CSS 文件放在头部了。
另外,JS 文件也不是不可以放在头部,只要给 script 标签加上 defer 属性就可以了,异步下载,延迟执行。
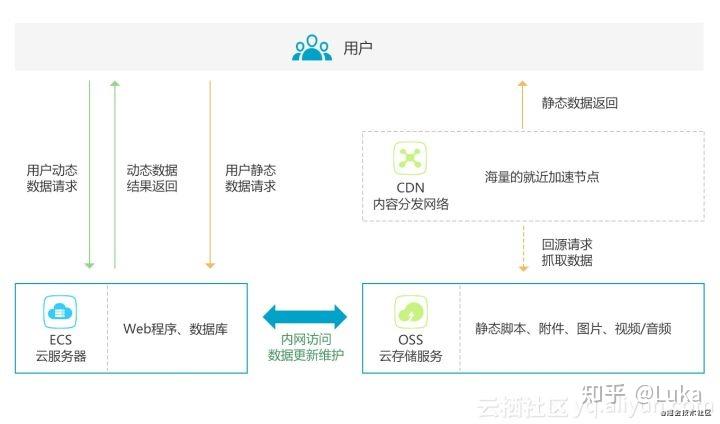
用户与服务器的物理距离对响应时间也有影响。把内容部署在多个地理位置分散的服务器上能让用户更快地载入页面, CDN就是为了解决这一问题,在多个位置部署服务器,让用户离服务器更近,从而缩短请求时间。
图片可以合并么?当然。最为常用的图片合并场景就是雪碧图(Sprite)。
在网站上通常会有很多小的图标,不经优化的话,最直接的方式就是将这些小图标保存为一个个独立的图片文件,然后通过 CSS 将对应元素的背景图片设置为对应的图标图片。这么做的一个重要问题在于,页面加载时可能会同时请求非常多的小图标图片,这就会受到浏览器并发 HTTP 请求数的限制。
雪碧图的核心原理在于设置不同的背景偏移量,大致包含两点:
background-url 设置为合并后的雪碧图的 uri;background-position 来展示大图中对应的图标部分。你可以用 Photoshop 这类工具自己制作雪碧图。当然比较推荐的还是将雪碧图的生成集成到前端自动化构建工具中,例如在 webpack 中使用 webpack-spritesmith,或者在 gulp 中使用 gulp.spritesmith。它们两者都是基于 spritesmith 这个库。一般来说,我们访问网站页面时,其实很多图片并不在首屏中,如果我们都加载的话,相当于是加载了用户不一定会看到图片, 这显然是一种浪费。解决的核心思路就是懒加载:实现方式就是先不给图片设置路径,当图片出现在浏览器可视区域时才设置真正的图片路径。
实现上就是先将图片路径设置给original-src,当页面不可见时,图片不会加载:
<img original-src="https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/9eb06680a16044feb794f40fc3b1ac3d~tplv-k3u1fbpfcp-watermark.image" />
通过监听页面滚动,等页面可见时设置图片src:
const img = document.querySelector('img')
img.src = img.getAttribute("original-src")
如果想使用懒加载,还可以借助一些已有的工具库,例如 aFarkas/lazysizes、verlok/lazyload、tuupola/lazyload 等。
除了对于 <img> 元素的图片进行来加载,在 CSS 中使用的图片一样可以懒加载,最常见的场景就是 background-url。
.login {
background-url: url(/static/img/login.png);
}
对于上面这个样式规则,如果不应用到具体的元素,浏览器不会去下载该图片。所以你可以通过切换 className 的方式,放心得进行 CSS 中图片的懒加载。
有前端经验的开发者对这个概念一定不会陌生,浏览器下载完页面需要的所有资源后, 就开始渲染页面,主要经历这5个过程:
重排
当改变DOM元素位置或者大小时, 会导致浏览器重新生成Render树, 这个过程叫重排
重绘
当重新生成渲染树后, 将要将渲染树每个节点绘制到屏幕, 这个过程叫重绘。
重排触发时机
重排发生后的根本原理就是元素的几何属性发生改变, 所以从能够改变几何属性的角度入手:
二者关系:重排会导致重绘, 但是重绘不会导致重排
了解了重排和重绘这两个概念,我们还要知道重排和重绘的开销都是非常昂贵的,如果不停的改变页面的布局,就会造成浏览器消耗大量的开销在进行页面的计算上,这样容易造成页面卡顿。那么回到我们的问题如何减少重绘与重排呢?
DOM 的多个读操作(或多个写操作),应该放在一起。不要两个读操作之间,加入一个写操作。
// bad 强制刷新 触发四次重排+重绘
div.style.left = div.offsetLeft + 1 + 'px';
div.style.top = div.offsetTop + 1 + 'px';
div.style.right = div.offsetRight + 1 + 'px';
div.style.bottom = div.offsetBottom + 1 + 'px';
// good 缓存布局信息 相当于读写分离 触发一次重排+重绘
var curLeft = div.offsetLeft;
var curTop = div.offsetTop;
var curRight = div.offsetRight;
var curBottom = div.offsetBottom;
div.style.left = curLeft + 1 + 'px';
div.style.top = curTop + 1 + 'px';
div.style.right = curRight + 1 + 'px';
div.style.bottom = curBottom + 1 + 'px';
不要频发的操作样式,虽然现在大部分浏览器有渲染队列优化,但是在一些老版本的浏览器仍然存在效率低下的问题:
// 三次重排
div.style.left = '10px';
div.style.top = '10px';
div.style.width = '20px';
// 一次重排
el.style.cssText = 'left: 10px;top: 10px; width: 20px';
或者可以采用更改类名而不是修改样式的方式。
使用绝对定位会使的该元素单独成为渲染树中 body 的一个子元素,重排开销比较小,不会对其它节点造成太多影响。当你在这些节点上放置这个元素时,一些其它在这个区域内的节点可能需要重绘,但是不需要重排。
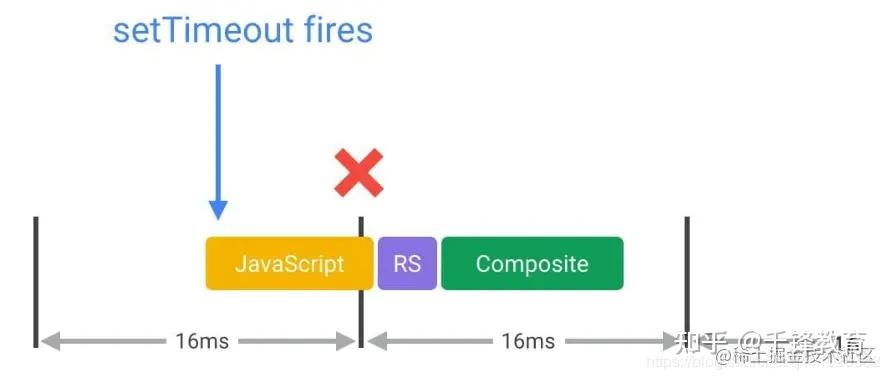
我们目前大多数屏幕的刷新率-60次/s,浏览器渲染更新页面的标准帧率也为60次/s --60FPS(frames/pre second), 那么每一帧的预算时间约为16.6ms ≈ 1s/60,浏览器在这个时间内要完成所有的整理工作,如果无法符合此预算, 帧率将下降,内容会在屏幕抖动, 此现象通常称为卡顿。
浏览器需要做的工作包含下面这个流程:

首先你用js做了些逻辑,还触发了样式变化,style把应用的样式规则计算好之后,把影响到的页面元素进行重新布局,叫做layout,再把它画到内存的一个画布里面,paint成了像素,最后把这个画布刷到屏幕上去,叫做composite,形成一帧。
这几项的任何一项如果执行时间太长了,就会导致渲染这一帧的时间太长,平均帧率就会掉。假设这一帧花了50ms,那么此时的帧率就为1s / 50ms=20fps.
当然上面的过程并不一定每一步都会执行,例如:
style只改了颜色等不需要重新layout的属性就不用执行layout这一步style改了transform属性,在blink和edge浏览器里面不需要layout和paint有时会有这样的需求, 需要在页面上展示包含上百个元素的列表(例如一个Feed流)。每个列表元素还有着复杂的内部结构,这显然提高了页面渲染的成本。当你使用了React时,长列表的问题就会被进一步的放大。那么怎么来优化长列表呢?
虚拟列表是一种用来优化长列表的技术。它可以保证在列表元素不断增加,或者列表元素很多的情况下,依然拥有很好的滚动、浏览性能。它的核心思想在于:只渲染可见区域附近的列表元素。下图左边就是虚拟列表的效果,可以看到只有视口内和临近视口的上下区域内的元素会被渲染。
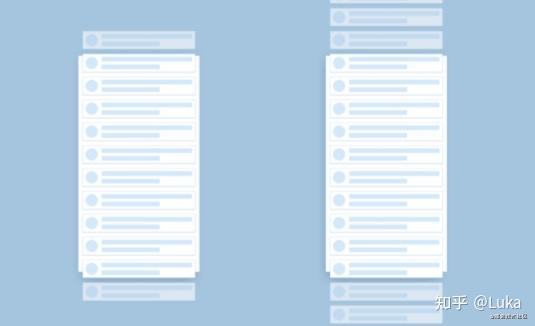
具体实现步骤如下所示:
offset重新计算应该在可视区内的子列表元素。这样保证了无论如何滚动,真实渲染出的dom节点只有可视区内的列表元素。position:relative,子元素的定位一般使用:position:absolute或sticky除了自己实现外, 常用的框架也有不错的开源实现, 例如:
react-virtualizedvue-virtual-scroll-listngx-virtual-scroller前端最容易碰到的性能问题的场景之一就是监听滚动事件并进行相应的操作。由于滚动事件发生非常频繁,所以频繁地执行监听回调就容易造成JavaScript执行与页面渲染之间互相阻塞的情况。
对应滚动这个场景,可以采用防抖和节流来处理。
当一个事件频繁触发,而我们希望间隔一定的时间再触发相应的函数时, 就可以使用节流(throttle)来处理。比如判断页面是否滚动到底部,然后展示相应的内容;就可以使用节流,在滚动时每300ms进行一次计算判断是否滚动到底部的逻辑,而不用无时无刻地计算。
当一个事件频繁触发,而我们希望在事件触发结束一段时间后(此段时间内不再有触发)才实际触发响应函数时会使用防抖(debounce)。例如用户一直点击按钮,但你不希望频繁发送请求,你就可以设置当点击后 200ms 内用户不再点击时才发送请求。
前面提到了大量数据的渲染环节我们可以采用虚拟列表的方式实现,但是大量数据的计算环节依然会产生浏览器假死或者卡顿的情况.
通常情况下我们CPU密集型的任务都是交给后端计算的,但是有些时候我们需要处理一些离线场景或者解放后端压力,这个时候此方法就不奏效了.
还有一种方法是计算切片,使用 setTimeout 拆分密集型任务,但是有些计算无法利用此方法拆解,同时还可能产生副作用,这个方法需要视具体场景而动.
最后一种方法也是目前比较奏效的方法就是利用Web Worker 进行多线程编程.
Web Worker 是一个独立的线程(独立的执行环境),这就意味着它可以完全和 UI 线程(主线程)并行的执行 js 代码,从而不会阻塞 UI,它和主线程是通过 onmessage 和 postMessage 接口进行通信的。
Web Worker 使得网页中进行多线程编程成为可能。当主线程在处理界面事件时,worker 可以在后台运行,帮你处理大量的数据计算,当计算完成,将计算结果返回给主线程,由主线程更新 DOM 元素。
提升性能,有时候在我们写代码时注意一些细节也是有效果的。
看一下下面这段代码:
<ul>
<li>字节跳动</li>
<li>阿里</li>
<li>腾讯</li>
<li>京东</li>
</ul>
// good
document.querySelector('ul').onclick = (event) => {
const target = event.target
if (target.nodeName === 'LI') {
console.log(target.innerHTML)
}
}
// bad
document.querySelectorAll('li').forEach((e) => {
e.onclick = function() {
console.log(this.innerHTML)
}
})
绑定的事件越多, 浏览器内存占有就越多,从而影响性能,利用事件代理的方式就可节省一些内存。
当判定条件越来越多时, 越倾向于使用switch,而不是if-else:
if (state ==0) {
console.log("待开通")
} else if (state == 1) {
console.log("学习中")
} else if (state == 2) {
console.log("休学中")
} else if (state == 3) {
console.log("已过期")
} esle if (state ==4){
console.log("未购买")
}
switch (state) {
case 0:
break
case 1:
break
case 2:
break
case 3:
break
case 4:
break
}
向上面这种情况使用switch更好, 假设state为4,那么if-else语句就要进行4次判定,switch只要进行一次即可。
但是有的情况下switch也做不到if-else的事情, 例如有多个判断条件的情况下,无法使用switch
在早期的 CSS 布局方式中我们能对元素实行绝对定位、相对定位或浮动定位。而现在,我们有了新的布局方式 flexbox,它比起早期的布局方式来说有个优势,那就是性能比较好。
欢迎大家前来讨论各种前端问题,感谢关注,感谢支持。
小伙伴们前端面试的时候经常会被问到关于性能优化方面的问题,那么这篇文章会详细的解释性能优化解决方法之一“文档碎片”。
一般情况下,在操作DOM结构的时候,经常会说非常消耗性能,原因是我们向DOM中添加新的元素,DOM会立刻更新。也就是添加一次更新一次,如果添加100个节点,那么就得更新100次,很浪费资源呀。

每次操作DOM节点插入时,浏览器会触发重排重绘,为了提高效率,要尽可能的减少重排重绘,即应该减少DOM节点的插入。有一种方法就是利用文档碎片去做。
文档碎片是一种虚拟的DOM节点,存在于内存中,跟实际的DOM节点之间没有关系,当我们需要给一个节点中插入多个子节点的时候,完全可以将多个子节点先插入到文档碎片中,所有子节点都放到文档碎片中后,再将文档碎片插入到实际的节点中,这样就减少了很多节点直接插入到父节点中的次数了,也就是本来多次触发重排重绘的操作,有了文档碎片中,只需要触发一次重排重绘了。
文档碎片创建:
document.createDocumentFragment()这个方法返回一个文档碎片,即虚拟DOM节点。
对于文档碎片的插入操作,跟实际的DOM节点操作是一样的。
例:
for(var i=1;i<=5;i++){
var p=document.createElement('p')
p.innerText=i
list.appendChild(p)
}通过循环创建了5个p标签,每创建一个就将这个p标签。创建插入的节点较少时,页面会立马发生变化。但一旦创建插入的节点多了以后,这个过程就可能会十分缓慢,例如插入10000条。
当然也可以提前先创建一个空节点,将所有子节点插入到这个节点中,然后再将这个节点插入到目标节点中。
var oDiv=document.createElement('div');
for(var i=1;i<=10000;i++){
var p=document.createElement('p');
p.innerText=i;
oDiv.appendChild(p);
}
list.appendChild(oDiv);但这样会会在list中多嵌套一个div标签。
而文档碎片的意义跟这个div一样,但不会多嵌套标签。
例:
var oFragmeng=document.createDocumentFragment();
for(var i=1;i<=10000;i++){
var p=document.createElement('p');
p.innerText=i;
oFragmeng.appendChild(p);
}
list.appendChild(oFragmeng);经过测试,在各个浏览器下性能明显得到提高。
当我们疲于开发一个接一个的需求时,很容易忘记去关注网站的性能,到了某一个节点,猛地发现,随着越来越多代码的堆积,网站变得越来越慢。
本文就是从这样的一个背景出发,着手优化网站的前端性能,并总结出一套开发习惯,让我们在日常开发时,也保持高性能,而不是又一次回过头来优化性能。
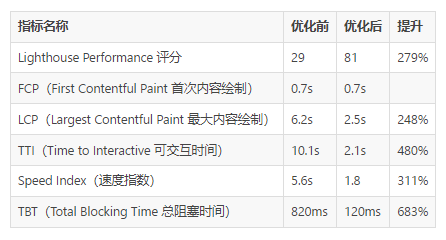
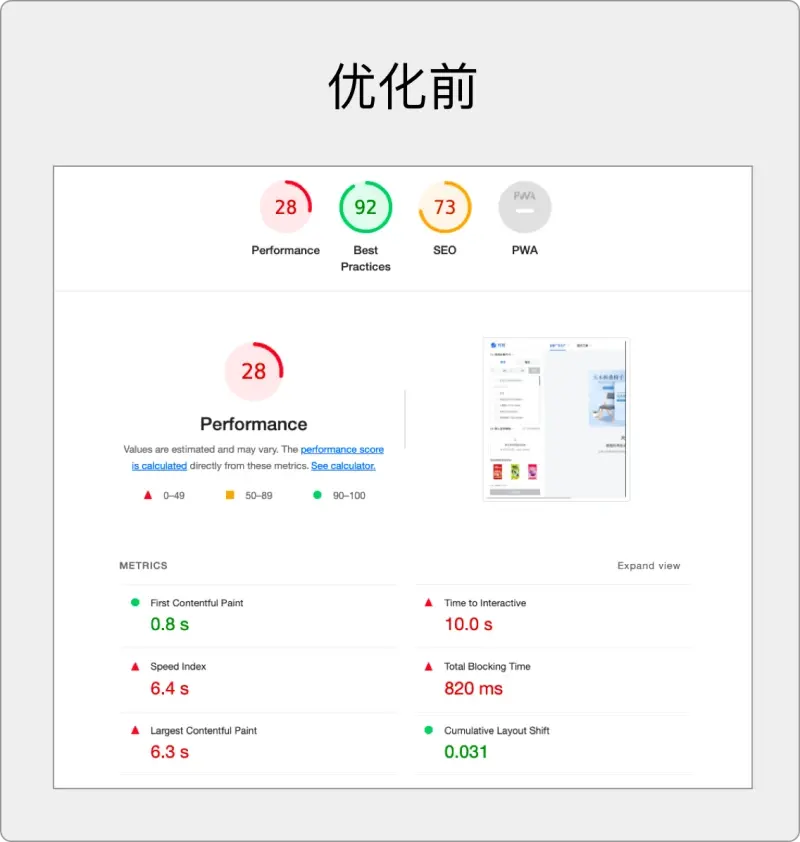
优化前后对比:
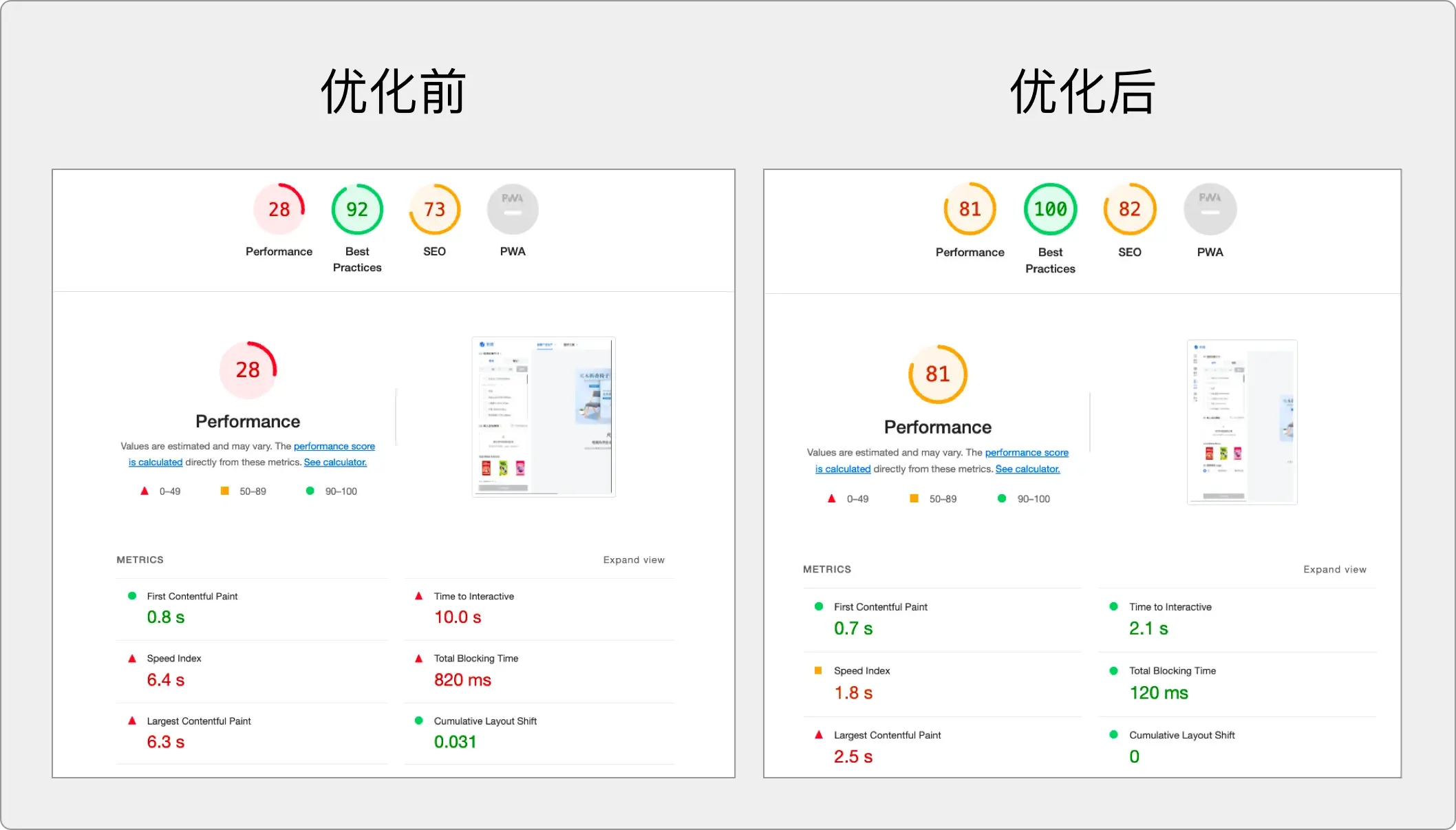
接下来就是介绍下优化前我们要做哪些事件:
一开始我们只是感受到网站的页面打开时白屏时间较长,感觉性能是比较差的,那么具体有哪些性能指标需要去关注呢?
这里我使用的是 Chrome devtools 内置的 Lighthouse,Lighthouse 是一种开源的自动化工具,用于提高 Web 应用程序的质量。
Lighthouse 会在一系列的测试下运行网页,比如不同尺寸的设备和不同的网络速度。它还会检查页面对辅助功能指南的一致性,例如颜色对比度和 ARIA 最佳实践。
打开 Chrome devtools Lighthouse 即可使用。
在比较短的时间内,Lighthouse 可以给出这样一份报告。
这份报告从 5 个方面来分析页面: 性能、辅助功能、最佳实践、搜索引擎优化和 PWA。像性能方面,会给出一些常见的耗时统计。
Performance 评分统计,包括了以下指标:
1.1.1 FCP
FCP 测量在用户导航到页面后浏览器呈现第一段 DOM 内容所花费的时间。页面上的图像、非白色 <canvas> 元素和 SVG 被视为 DOM 内容;不包括 iframe 内的任何内容。
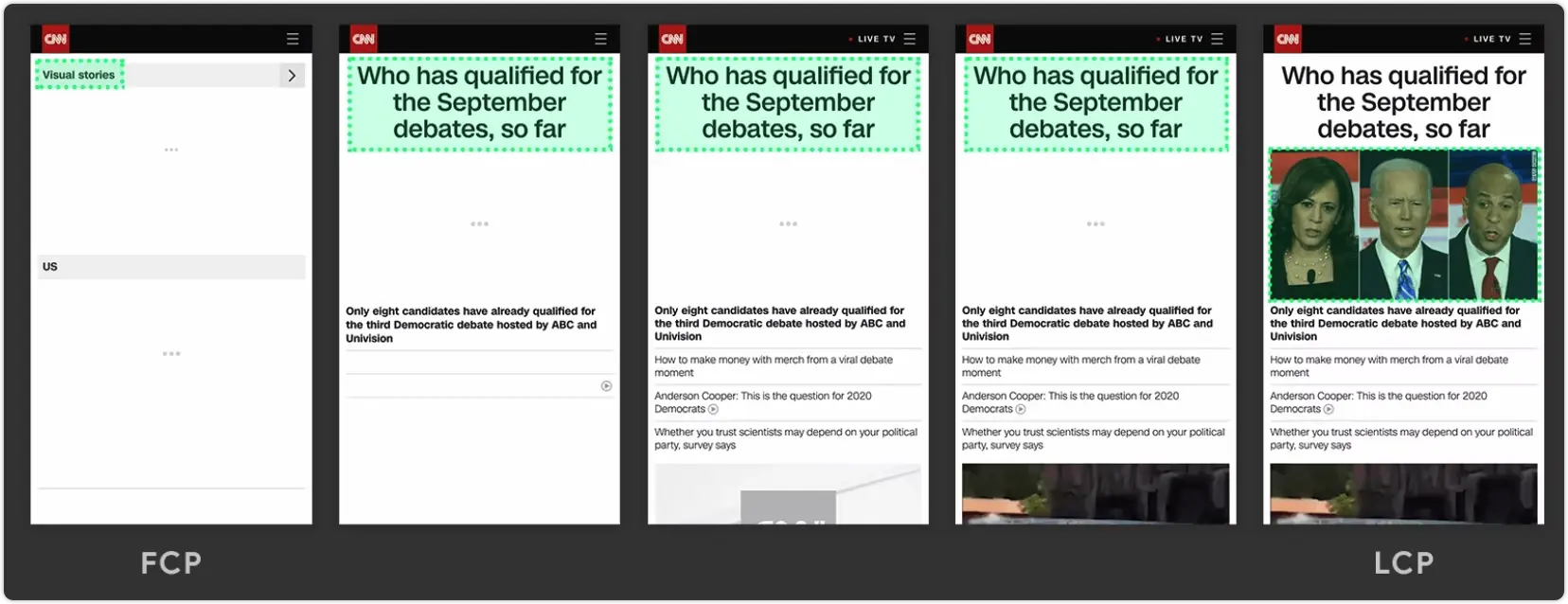
1.1.2 LCP
LCP 测量视口中最大的内容元素何时呈现到屏幕上。这近似于页面的主要内容对用户可见的时间。
需要注意的是 LCP 的计算是一个动态的过程,如下图最后的图片才是这个页面中的最大内容绘制的元素。
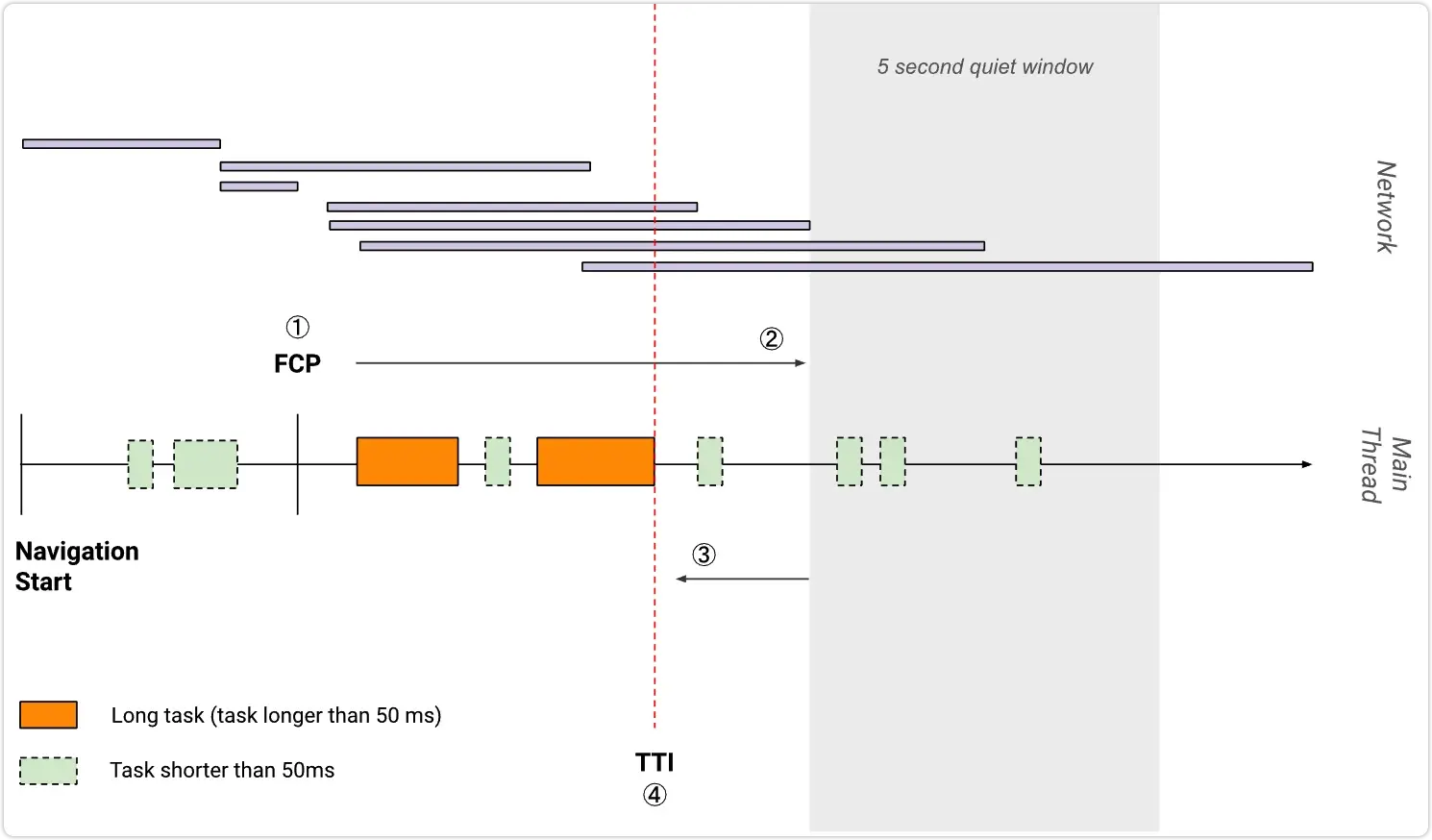
1.1.3 TTI
TTI 测量页面完全交互所需的时间。
TTI 是如何计算的呢,如下图首先延时间轴正向搜索时长至少为 5 秒的安静窗口(安静窗口是指没有长任务且不超过两个正在处理的网络 get 请求),然后沿时间轴反向搜索安静窗口之前的最后一个长任务,如果没有找到长任务,则在 FCP 步骤停止执行,TTI 就是安静窗口之前最后一个长任务的结束时间,如果没有找到长任务的话,则与 FCP 值相同。
1.1.4 Speed Index
Speed Index 衡量页面加载期间内容以视觉方式显示的速度。Lighthouse 首先捕获浏览器中页面加载的视频,并计算帧之间的视觉进度。
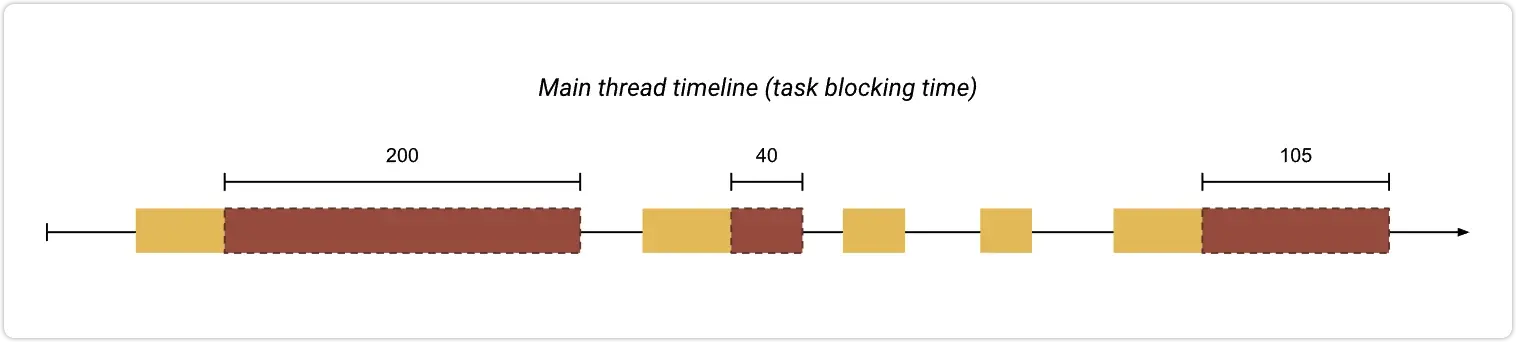
1.1.5 TBT
TBT 测量页面被阻止响应用户输入(例如鼠标点击、屏幕点击或键盘按下)的总时间。
通过添加 First Contentful Paint 和 Time to Interactive 之间所有长任务的阻塞部分来计算总和。任何执行时间超过 50 毫秒的任务都是长任务。
50 毫秒后的时间量是阻塞部分。例如,如果 Lighthouse 检测到一个 70 毫秒长的任务,则阻塞部分将为 20 毫秒。
如下图淡红色区域的时间总和就是这个页面的 TBT 分数。
用于检测 Web 应用程序整体代码健康状况,包括是否包含文档类型、图片宽高比是否正确等等。
用于检测搜索引擎对网页内容的理解程度。
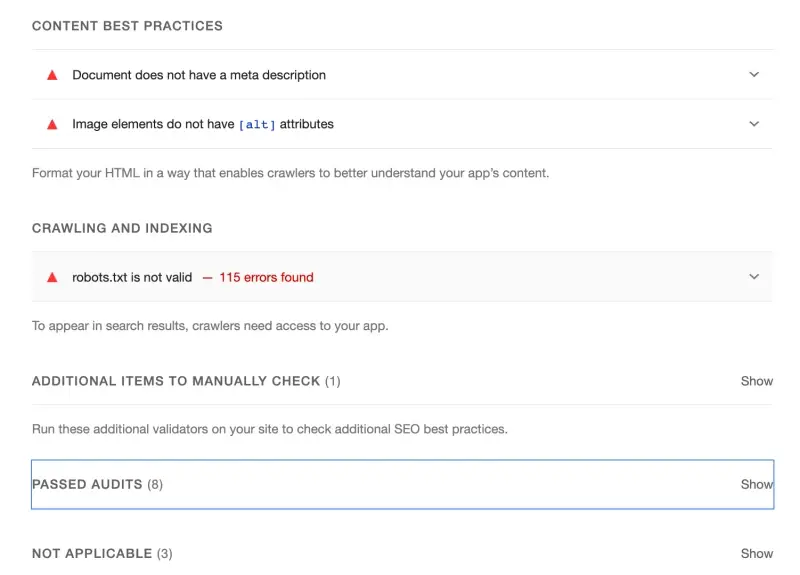
了解了关键的性能指标后,就可以测量看看当前网站的性能了,
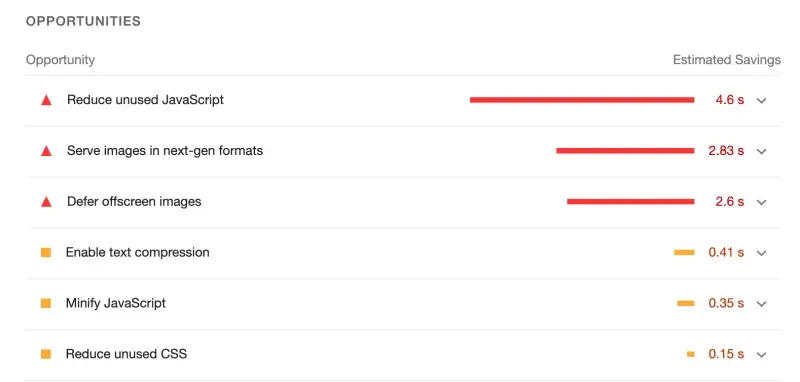
上面看到综合评分是非常低的,Lighthouse 给出了应该从哪些地方开始优化的建议。
性能优化建议主要包括以下几点:
Lighthouse 诊断出的网站存在的问题:
{passive: true}),导致需要等待侦听器完成执行后再滚动页面;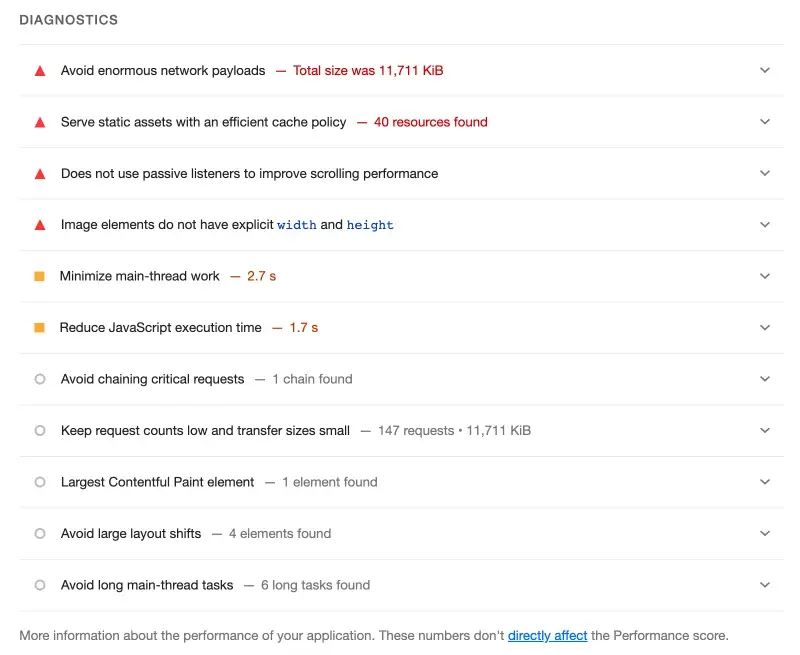
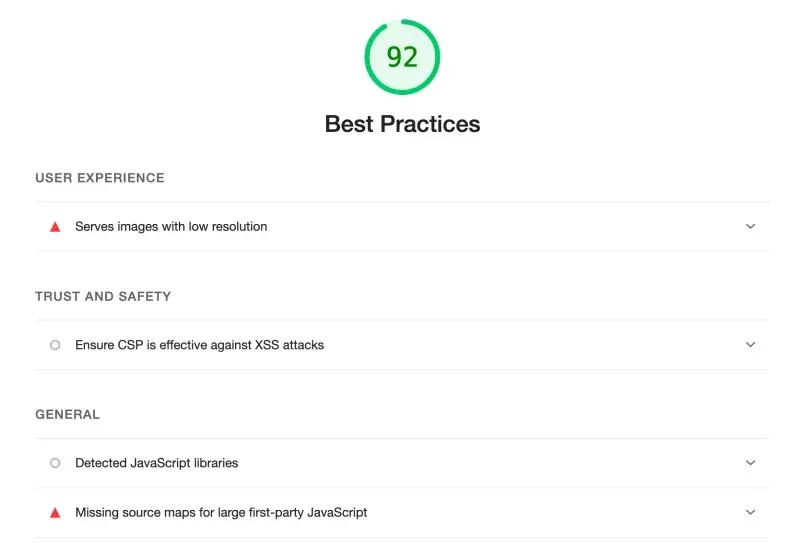
最佳实践方面有以下问题:
SEO 有以下问题:
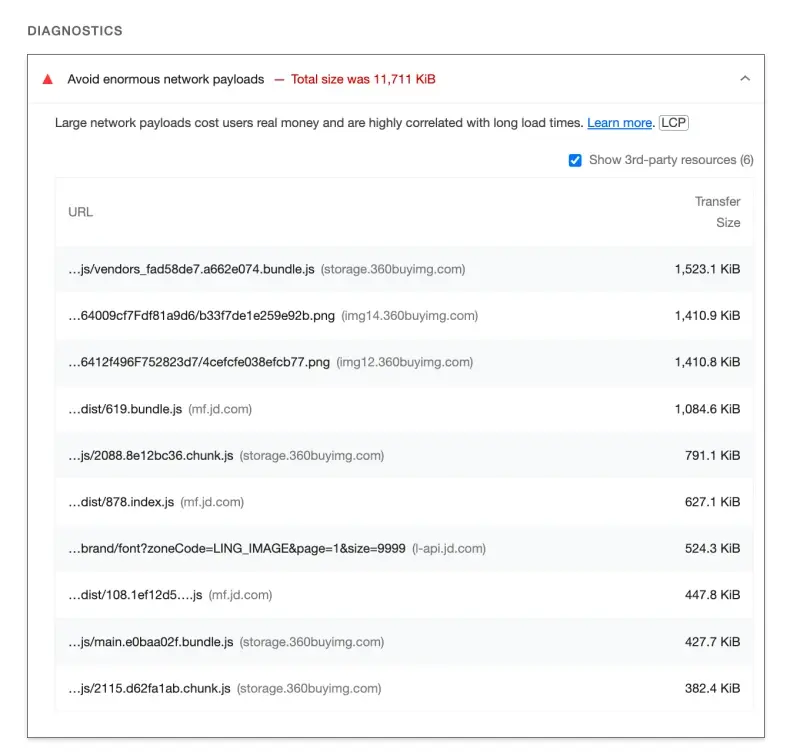
根据上面 Lighthouse 报告,捋一捋项目中影响性能最大的因素,包括以下几点:
检查是否还有压缩空间,或者有无工具库未压缩的。
通过 webpack-bundle-analyzer 插件分析包体积,将一些大的 npm 包和 runtimeChunk 独立分包,减小包体积。
React.lazy + Suspense 封装懒加载组件,路由级组件引入懒加载组件。
同时使用骨架屏作为懒加载的兜底组件,可以让用户感知加载更快。
在鼠标移入导航栏时预加载路由组件,可以加快页面展示。
通过 import ('xx').then (xx) 按需加载工具库。
项目内有一些 json 文件存储的静态数据,这部分文件上传至 CDN,改为 fetch 的方式按需引入。
检查项目中引入的 mf、npm 资源,将没有使用到的删除。
发现业务组件库通过 npm 引入的原子组件库,而项目本身又是通过 mf 引入的原子组件库,相对于引入了 2 遍原子组件库。
这时就需要改造业务组件库,也改成用 mf 的方法引入。
因为 webpack 的按需加载是通过 import、export 来标记的,因此想要一个好的按需加载的效果,就需要避免依赖嵌套的问题。
原子组件库 mf 暴露的方式会导致只用了 1 个 icon,就会加载组件库下所有 icon 对应的 chunk,导致资源浪费。
新建一个 icon 的 npm 包用于 icon 的按需引入。
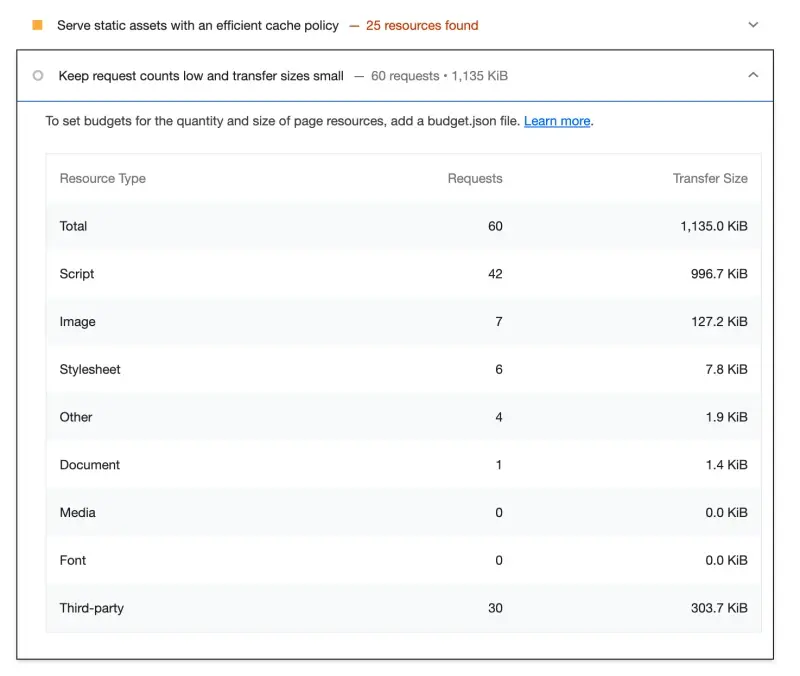
通过以上优化手段,体积从 11.7mb 降低至 1.1mb,降低 10.6 倍。
优化前:
优化后:
对非首屏的图片采用图片懒加载策略。
使用图片时,设置图片的合理尺寸。
优先使用 webp 格式图片。
优化项目内的图片分辨率。
详细的 meta description、keywords 可以加快 SEO。
<meta name="keywords" content="xx" /> <meta name="description" content="xx" /><img src=https://www.zhihu.com/question/"smiley.gif" alt="Smiley face" />再来回顾下前后对比:
优化前,明显的感知白屏时间长:
优化后,在清缓存的情况下也能实现秒开:
整体性能提升 270%:
为了在后续的迭代过程中,保持高性能,引入内部前端监控平台 - 烛龙,可视化的监控前端性能。
第一步,加载 cdn 插件:
<script
defer
src=https://www.zhihu.com/question/"https://h5static.m.jd.com/act/jd-jssdk/latest/jd-jssdk.min.js"
></script>第二步,在入口文件中,初始化 cdn 插件:
useEffect(()=>{
// 初始化测速组件,在这里可以打开一些控制的开关,如是否上报接口
if (IS_PROD){
// @ts-ignore
jmfe.profilerInit({
flag: xxx, // 这是应用ID,需要先在烛龙申请应用
autoReport: true,
autoAddStaticReport: true,
autoAddApiReport: true,
autoAddImageReport: false, // 支持所有图片上报,如果图片多,切记关闭,否则存在性能问题
performanceReportTime: 8000,
profilingRate: 1,
})
}
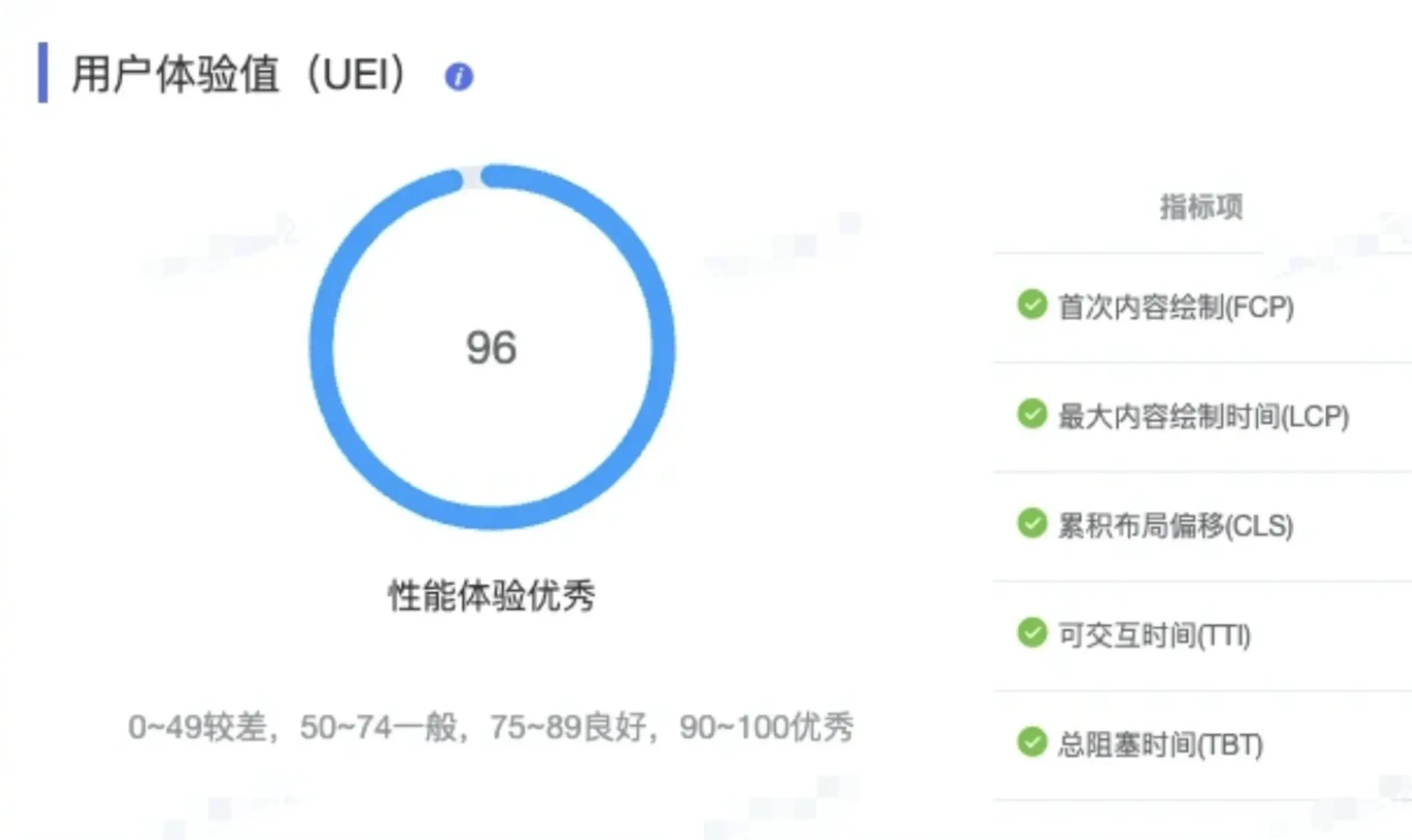
},[])第三步,查看监控数据:
在烛龙平台,小工具性能评分达 96 分:
第四步,新增告警,实时监控
烛龙平台支持多维度的告警的服务,增加性能指标相关的告警,在性能异动时,及时发现问题,优化性能。
本文详细介绍了一个前端项目优化的详细过程,从优化前的问题分析,到具体的优化措施,最终实现了前端性能提升了近 3 倍。同时也将性能指标落到监控平台,实现可视化的监控前端性能指标。
希望能对你有所帮助,感谢阅读~
作者:京东零售 唐姣
来源:京东云开发者社区
要想全面的回答该问题,需要从前端发出请求到页面完成展示整个流程去阐述。
整个流程大致可以分为3个阶段:请求页面,加载和解析页面,渲染。
使用http DNS 缓存、减少重定向、静态资源开启压缩及gzip、开启多域名请求、长链接、合理利用服务器缓存/分布式等
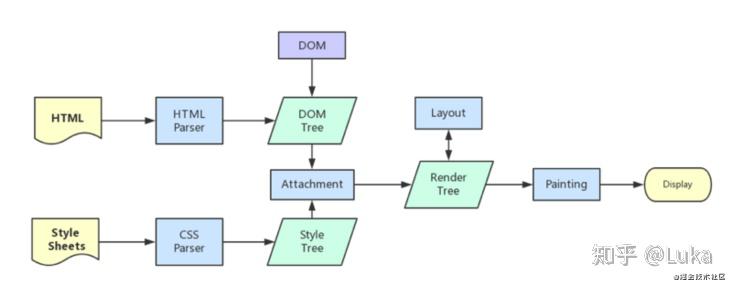
需要了解浏览器加载和渲染机制:① 开始解析HTML(DOM Tree)=> ② 获取外部资源=> ③ 解析 CSS 并构建CSSOM=> ④ 执行 JavaScript=> ⑤ 合并 DOM 和 CSSOM 以构造渲染树=> ⑥ 计算布局和绘制
使用 defer/async、动态/延迟加载等
需要关注两个过程:重排&重绘。
避免方式:
transform是位于Composite Layers层)性能优化是把双刃剑,有好的一面也有坏的一面。好的一面就是能提升网站性能,坏的一面就是配置麻烦,或者要遵守的规则太多。并且某些性能优化规则并不适用所有场景,需要谨慎使用,请读者带着批判性的眼光来阅读本文。
一个完整的 HTTP 请求需要经历 DNS 查找,TCP 握手,浏览器发出 HTTP 请求,服务器接收请求,服务器处理请求并发回响应,浏览器接收响应等过程。接下来看一个具体的例子帮助理解 HTTP :
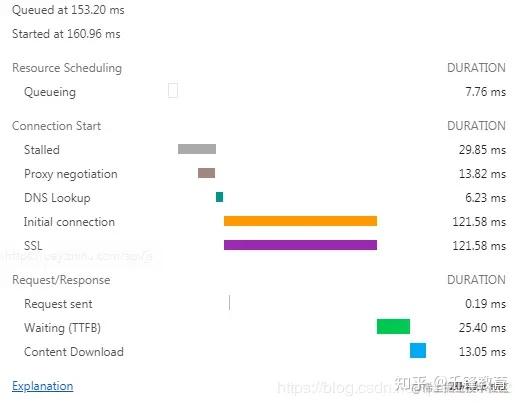
这是一个 HTTP 请求,请求的文件大小为 28.4KB。
名词解释:
从这个例子可以看出,真正下载数据的时间占比为 13.05 / 204.16=6.39%,文件越小,这个比例越小,文件越大,比例就越高。这就是为什么要建议将多个小文件合并为一个大文件,从而减少 HTTP 请求次数的原因。
HTTP2 相比 HTTP1.1 有如下几个优点:
服务器解析 HTTP1.1 的请求时,必须不断地读入字节,直到遇到分隔符 CRLF 为止。而解析 HTTP2 的请求就不用这么麻烦,因为 HTTP2 是基于帧的协议,每个帧都有表示帧长度的字段。
HTTP1.1 如果要同时发起多个请求,就得建立多个 TCP 连接,因为一个 TCP 连接同时只能处理一个 HTTP1.1 的请求。
在 HTTP2 上,多个请求可以共用一个 TCP 连接,这称为多路复用。同一个请求和响应用一个流来表示,并有唯一的流 ID 来标识。 多个请求和响应在 TCP 连接中可以乱序发送,到达目的地后再通过流 ID 重新组建。
HTTP2 提供了首部压缩功能。
例如有如下两个请求:
:authority: unpkg.zhimg.com
:method: GET
:path: /za-js-sdk@2.16.0/dist/zap.js
:scheme: https
accept: */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
cache-control: no-cache
pragma: no-cache
referer: https://www.zhihu.com/
sec-fetch-dest: script
sec-fetch-mode: no-cors
sec-fetch-site: cross-site
user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
makefile复制代码
:authority: zz.bdstatic.com
:method: GET
:path: /linksubmit/push.js
:scheme: https
accept: */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
cache-control: no-cache
pragma: no-cache
referer: https://www.zhihu.com/
sec-fetch-dest: script
sec-fetch-mode: no-cors
sec-fetch-site: cross-site
user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
从上面两个请求可以看出来,有很多数据都是重复的。如果可以把相同的首部存储起来,仅发送它们之间不同的部分,就可以节省不少的流量,加快请求的时间。
HTTP/2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送。
下面再来看一个简化的例子,假设客户端按顺序发送如下请求首部:
Header1:foo
Header2:bar
Header3:bat当客户端发送请求时,它会根据首部值创建一张表:
| 索引 | 首部名称 | 值 |
|---|---|---|
| 62 | Header1 | foo |
| 63 | Header2 | bar |
| 64 | Header3 | bat |
如果服务器收到了请求,它会照样创建一张表。 当客户端发送下一个请求的时候,如果首部相同,它可以直接发送这样的首部块:
62 63 64服务器会查找先前建立的表格,并把这些数字还原成索引对应的完整首部。
HTTP2 可以对比较紧急的请求设置一个较高的优先级,服务器在收到这样的请求后,可以优先处理。
由于一个 TCP 连接流量带宽(根据客户端到服务器的网络带宽而定)是固定的,当有多个请求并发时,一个请求占的流量多,另一个请求占的流量就会少。流量控制可以对不同的流的流量进行精确控制。
HTTP2 新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。换句话说,除了对最初请求的响应外,服务器还可以额外向客户端推送资源,而无需客户端明确地请求。
例如当浏览器请求一个网站时,除了返回 HTML 页面外,服务器还可以根据 HTML 页面中的资源的 URL,来提前推送资源。
现在有很多网站已经开始使用 HTTP2 了,例如知乎:
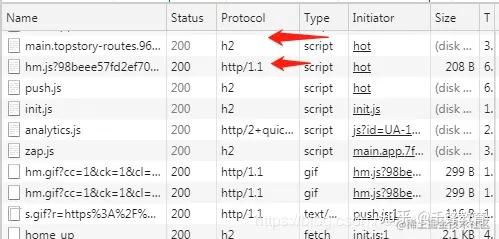
其中 h2 是指 HTTP2 协议,http/1.1 则是指 HTTP1.1 协议。
客户端渲染: 获取 HTML 文件,根据需要下载 JavaScript 文件,运行文件,生成 DOM,再渲染。
服务端渲染:服务端返回 HTML 文件,客户端只需解析 HTML。
下面我用 Vue SSR 做示例,简单的描述一下 SSR 过程。
<div id="app"></div> 的 HTML 文件。new Vue() 开始实例化并渲染页面。new Vue() 开始实例化并接管页面。从上述两个过程中可以看出,区别就在于第二步。客户端渲染的网站会直接返回 HTML 文件,而服务端渲染的网站则会渲染完页面再返回这个 HTML 文件。
这样做的好处是什么?是更快的内容到达时间 (time-to-content)。
假设你的网站需要加载完 abcd 四个文件才能渲染完毕。并且每个文件大小为 1 M。
这样一算:客户端渲染的网站需要加载 4 个文件和 HTML 文件才能完成首页渲染,总计大小为 4M(忽略 HTML 文件大小)。而服务端渲染的网站只需要加载一个渲染完毕的 HTML 文件就能完成首页渲染,总计大小为已经渲染完毕的 HTML 文件(这种文件不会太大,一般为几百K,我的个人博客网站(SSR)加载的 HTML 文件为 400K)。这就是服务端渲染更快的原因。
内容分发网络(CDN)是一组分布在多个不同地理位置的 Web 服务器。我们都知道,当服务器离用户越远时,延迟越高。CDN 就是为了解决这一问题,在多个位置部署服务器,让用户离服务器更近,从而缩短请求时间。
当用户访问一个网站时,如果没有 CDN,过程是这样的:
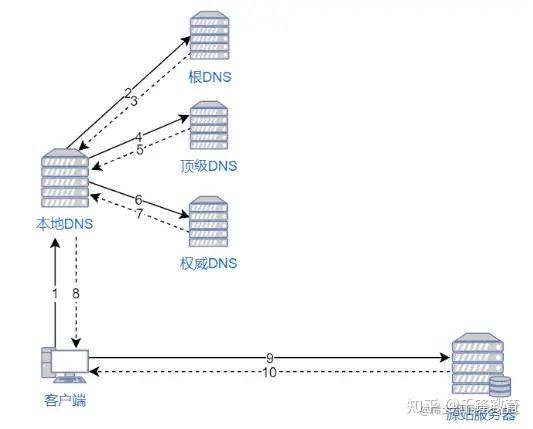
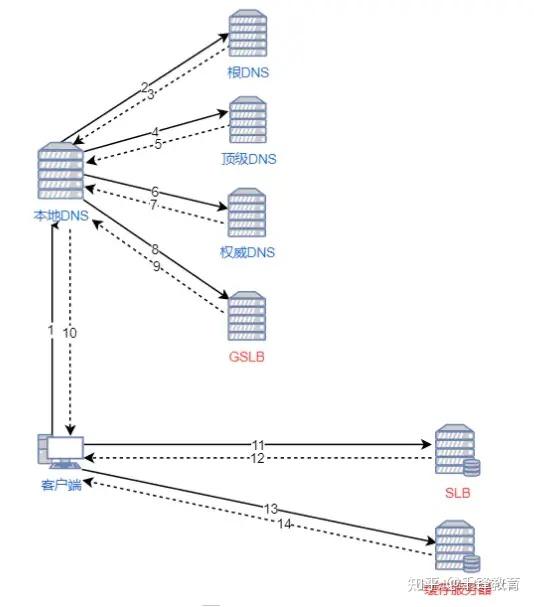
如果用户访问的网站部署了 CDN,过程是这样的:
如果这些 CSS、JS 标签放在 HEAD 标签里,并且需要加载和解析很久的话,那么页面就空白了。所以 JS 文件要放在底部(不阻止 DOM 解析,但会阻塞渲染),等 HTML 解析完了再加载 JS 文件,尽早向用户呈现页面的内容。
那为什么 CSS 文件还要放在头部呢?
因为先加载 HTML 再加载 CSS,会让用户第一时间看到的页面是没有样式的、“丑陋”的,为了避免这种情况发生,就要将 CSS 文件放在头部了。
另外,JS 文件也不是不可以放在头部,只要给 script 标签加上 defer 属性就可以了,异步下载,延迟执行。
字体图标就是将图标制作成一个字体,使用时就跟字体一样,可以设置属性,例如 font-size、color 等等,非常方便。并且字体图标是矢量图,不会失真。还有一个优点是生成的文件特别小。
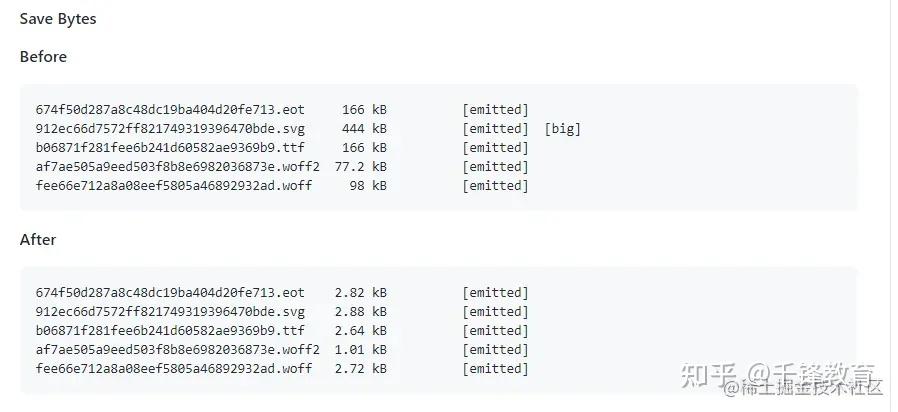
压缩字体文件
使用 fontmin-webpack 插件对字体文件进行压缩。
为了避免用户每次访问网站都得请求文件,我们可以通过添加 Expires 或 max-age 来控制这一行为。Expires 设置了一个时间,只要在这个时间之前,浏览器都不会请求文件,而是直接使用缓存。而 max-age 是一个相对时间,建议使用 max-age 代替 Expires 。
不过这样会产生一个问题,当文件更新了怎么办?怎么通知浏览器重新请求文件?
可以通过更新页面中引用的资源链接地址,让浏览器主动放弃缓存,加载新资源。
具体做法是把资源地址 URL 的修改与文件内容关联起来,也就是说,只有文件内容变化,才会导致相应 URL 的变更,从而实现文件级别的精确缓存控制。什么东西与文件内容相关呢?我们会很自然的联想到利用数据摘要要算法对文件求摘要信息,摘要信息与文件内容一一对应,就有了一种可以精确到单个文件粒度的缓存控制依据了。
压缩文件可以减少文件下载时间,让用户体验性更好。
得益于 webpack 和 node 的发展,现在压缩文件已经非常方便了。
在 webpack 可以使用如下插件进行压缩:
其实,我们还可以做得更好。那就是使用 gzip 压缩。可以通过向 HTTP 请求头中的 Accept-Encoding 头添加 gzip 标识来开启这一功能。当然,服务器也得支持这一功能。
gzip 是目前最流行和最有效的压缩方法。举个例子,我用 Vue 开发的项目构建后生成的 app.js 文件大小为 1.4MB,使用 gzip 压缩后只有 573KB,体积减少了将近 60%。
附上 webpack 和 node 配置 gzip 的使用方法。
下载插件
npm install compression-webpack-plugin --save-dev
npm install compressio
webpack 配置
const CompressionPlugin=require('compression-webpack-plugin');
module.exports={
plugins:[new CompressionPlugin()],
}
node 配置
const compression=require('compression')
// 在其他中间件前使用
app.use(compression())
在页面中,先不给图片设置路径,只有当图片出现在浏览器的可视区域时,才去加载真正的图片,这就是延迟加载。对于图片很多的网站来说,一次性加载全部图片,会对用户体验造成很大的影响,所以需要使用图片延迟加载。
首先可以将图片这样设置,在页面不可见时图片不会加载:
<img data-src=https://www.zhihu.com/question/"https://avatars0.githubusercontent.com/u/22117876?s=460&u=7bd8f32788df6988833da6bd155c3cfbebc68006&v=4">
等页面可见时,使用 JS 加载图片:
const img=document.querySelector('img')
img.src=https://www.zhihu.com/question/img.dataset.src
这样图片就加载出来了,完整的代码可以看一下参考资料。
响应式图片的优点是浏览器能够根据屏幕大小自动加载合适的图片。
通过 picture 实现
<picture>
<source srcset="banner_w1000.jpg" media="(min-width: 801px)">
<source srcset="banner_w800.jpg" media="(max-width: 800px)">
<img src=https://www.zhihu.com/question/"banner_w800.jpg" alt="">
</picture>
通过 @media 实现
@media (min-width: 769px){
.bg{
background-image: url(bg1080.jpg);
}
}
@media (max-width: 768px){
.bg{
background-image: url(bg768.jpg);
}
}
例如,你有一个 1920 * 1080 大小的图片,用缩略图的方式展示给用户,并且当用户鼠标悬停在上面时才展示全图。如果用户从未真正将鼠标悬停在缩略图上,则浪费了下载图片的时间。
所以,我们可以用两张图片来实行优化。一开始,只加载缩略图,当用户悬停在图片上时,才加载大图。还有一种办法,即对大图进行延迟加载,在所有元素都加载完成后手动更改大图的 src 进行下载。
例如 JPG 格式的图片,100% 的质量和 90% 质量的通常看不出来区别,尤其是用来当背景图的时候。我经常用 PS 切背景图时, 将图片切成 JPG 格式,并且将它压缩到 60% 的质量,基本上看不出来区别。
压缩方法有两种,一是通过 webpack 插件 image-webpack-loader,二是通过在线网站进行压缩。
以下附上 webpack 插件 image-webpack-loader 的用法。
npm i -D image-webpack-loader{
test: /\\.(png|jpe?g|gif|svg)(\\?.*)?$/,
use:[
{
loader: 'url-loader',
options:{
limit: 10000, /* 图片大小小于1000字节限制时会自动转成 base64 码引用*/
name: utils.assetsPath('img/[name].[hash:7].[ext]')
}
},
/*对图片进行压缩*/
{
loader: 'image-webpack-loader',
options:{
bypassOnDebug: true,
}
}
]
}
有很多图片使用 CSS 效果(渐变、阴影等)就能画出来,这种情况选择 CSS3 效果更好。因为代码大小通常是图片大小的几分之一甚至几十分之一。
WebP 的优势体现在它具有更优的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量;同时具备了无损和有损的压缩模式、Alpha 透明以及动画的特性,在 JPEG 和 PNG 上的转化效果都相当优秀、稳定和统一。
懒加载或者按需加载,是一种很好的优化网页或应用的方式。这种方式实际上是先把你的代码在一些逻辑断点处分离开,然后在一些代码块中完成某些操作后,立即引用或即将引用另外一些新的代码块。这样加快了应用的初始加载速度,减轻了它的总体体积,因为某些代码块可能永远不会被加载。
根据文件内容生成文件名,结合 import 动态引入组件实现按需加载
通过配置 output 的 filename 属性可以实现这个需求。filename 属性的值选项中有一个[contenthash],它将根据文件内容创建出唯一 hash。当文件内容发生变化时,[contenthash]也会发生变化。
output:{
filename: '[name].[contenthash].js',
chunkFilename: '[name].[contenthash].js',
path: path.resolve(__dirname, 'https://www.zhihu.com/dist'),
},
由于引入的第三方库一般都比较稳定,不会经常改变。所以将它们单独提取出来,作为长期缓存是一个更好的选择。 这里需要使用 webpack4 的 splitChunk 插件 cacheGroups 选项。
optimization:{
runtimeChunk:{
name: 'manifest' // 将 webpack 的 runtime 代码拆分为一个单独的 chunk。
},
splitChunks:{
cacheGroups:{
vendor:{
name: 'chunk-vendors',
test: /[\\\/]node_modules[\\\/]/,
priority: -10,
chunks: 'initial'
},
common:{
name: 'chunk-common',
minChunks: 2,
priority: -20,
chunks: 'initial',
reuseExistingChunk: true
}
},
}
},
Babel 转化后的代码想要实现和原来代码一样的功能需要借助一些帮助函数,比如:
class Person{}
会被转换为:
"use strict";
function _classCallCheck(instance, Constructor){
if (!(instance instanceof Constructor)){
throw new TypeError("Cannot call a class as a function");
}
}
var Person=function Person(){
_classCallCheck(this, Person);
};
这里 _classCallCheck 就是一个 helper 函数,如果在很多文件里都声明了类,那么就会产生很多个这样的 helper 函数。
这里的 @babel/runtime 包就声明了所有需要用到的帮助函数,而 @babel/plugin-transform-runtime 的作用就是将所有需要 helper 函数的文件,从 @babel/runtime包 引进来:
"use strict";
var _classCallCheck2=require("@babel/runtime/helpers/classCallCheck");
var _classCallCheck3=_interopRequireDefault(_classCallCheck2);
function _interopRequireDefault(obj){
return obj && obj.__esModule ? obj :{ default: obj };
}
var Person=function Person(){
(0, _classCallCheck3.default)(this, Person);
};
这里就没有再编译出 helper 函数 classCallCheck 了,而是直接引用了 @babel/runtime 中的 helpers/classCallCheck。
安装
npm i -D @babel/plugin-transform-runtime @babel/runtime
使用 在 .babelrc 文件中
"plugins":
[ "@babel/plugin-transform-runtime"
]
浏览器渲染过程
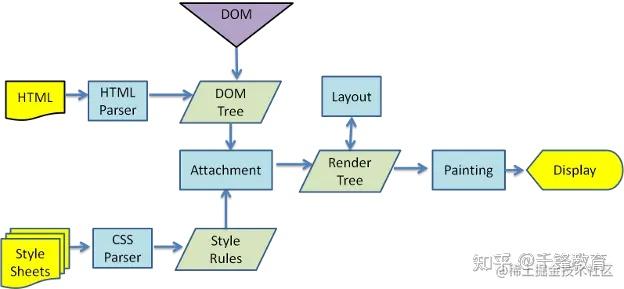
当改变 DOM 元素位置或大小时,会导致浏览器重新生成渲染树,这个过程叫重排。
当重新生成渲染树后,就要将渲染树每个节点绘制到屏幕,这个过程叫重绘。不是所有的动作都会导致重排,例如改变字体颜色,只会导致重绘。记住,重排会导致重绘,重绘不会导致重排 。
重排和重绘这两个操作都是非常昂贵的,因为 JavaScript 引擎线程与 GUI 渲染线程是互斥,它们同时只能一个在工作。
事件委托利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。所有用到按钮的事件(多数鼠标事件和键盘事件)都适合采用事件委托技术, 使用事件委托可以节省内存。
<ul>
<li>苹果</li>
<li>香蕉</li>
<li>凤梨</li>
</ul>
// good
document.querySelector('ul').onclick=(event)=>{
const target=event.target
if (target.nodeName==='LI'){
console.log(target.innerHTML)
}
}
// bad
document.querySelectorAll('li').forEach((e)=>{
e.onclick=function(){
console.log(this.innerHTML)
}
})
一个编写良好的计算机程序常常具有良好的局部性,它们倾向于引用最近引用过的数据项附近的数据项,或者最近引用过的数据项本身,这种倾向性,被称为局部性原理。有良好局部性的程序比局部性差的程序运行得更快。
局部性通常有两种不同的形式:
function sum(arry){
let i, sum=0
let len=arry.length
for (i=0; i < len; i++){
sum +=arry[i]
}
return sum
}
在这个例子中,变量sum在每次循环迭代中被引用一次,因此,对于sum来说,具有良好的时间局部性
具有良好空间局部性的程序
// 二维数组
function sum1(arry, rows, cols){
let i, j, sum=0
for (i=0; i < rows; i++){
for (j=0; j < cols; j++){
sum +=arry[i][j]
}
}
return sum
}
空间局部性差的程序
// 二维数组
function sum2(arry, rows, cols){
let i, j, sum=0
for (j=0; j < cols; j++){
for (i=0; i < rows; i++){
sum +=arry[i][j]
}
}
return sum
}
看一下上面的两个空间局部性示例,像示例中从每行开始按顺序访问数组每个元素的方式,称为具有步长为1的引用模式。 如果在数组中,每隔k个元素进行访问,就称为步长为k的引用模式。 一般而言,随着步长的增加,空间局部性下降。
这两个例子有什么区别?区别在于第一个示例是按行扫描数组,每扫描完一行再去扫下一行;第二个示例是按列来扫描数组,扫完一行中的一个元素,马上就去扫下一行中的同一列元素。
数组在内存中是按照行顺序来存放的,结果就是逐行扫描数组的示例得到了步长为 1 引用模式,具有良好的空间局部性;而另一个示例步长为 rows,空间局部性极差。
运行环境:
对一个长度为9000的二维数组(子数组长度也为9000)进行10次空间局部性测试,时间(毫秒)取平均值,结果如下:
所用示例为上述两个空间局部性示例
| 步长为 1 | 步长为 9000 |
|---|---|
| 124 | 2316 |
从以上测试结果来看,步长为 1 的数组执行时间比步长为 9000 的数组快了一个数量级。
总结:
当判断条件数量越来越多时,越倾向于使用 switch 而不是 if-else。
if (color=='blue'){
}else if (color=='yellow'){
}else if (color=='white'){
}else if (color=='black'){
}else if (color=='green'){
}else if (color=='orange'){
}else if (color=='pink'){
}
switch (color){
case 'blue':
break
case 'yellow':
break
case 'white':
break
case 'black':
break
case 'green':
break
case 'orange':
break
case 'pink':
break
}
像上面的这种情况,从可读性来说,使用 switch 是比较好的(js 的 switch 语句不是基于哈希实现,而是循环判断,所以说 if-else、switch 从性能上来说是一样的)。
当条件语句特别多时,使用 switch 和 if-else 不是最佳的选择,这时不妨试一下查找表。查找表可以使用数组和对象来构建。
switch (index){
case '0':
return result0
case '1':
return result1
case '2':
return result2
case '3':
return result3
case '4':
return result4
case '5':
return result5
case '6':
return result6
case '7':
return result7
case '8':
return result8
case '9':
return result9
case '10':
return result10
case '11':
return result11
}
可以将这个 switch 语句转换为查找表
const results=[result0,result1,result2,result3,result4,result5,result6,result7,result8,result9,result10,result11]
return results[index]
如果条件语句不是数值而是字符串,可以用对象来建立查找表
const map={ red: result0, green: result1, }return map[color]
60fps 与设备刷新率
目前大多数设备的屏幕刷新率为 60 次/秒。因此,如果在页面中有一个动画或渐变效果,或者用户正在滚动页面,那么浏览器渲染动画或页面的每一帧的速率也需要跟设备屏幕的刷新率保持一致。 其中每个帧的预算时间仅比 16 毫秒多一点 (1 秒/ 60=16.66 毫秒)。但实际上,浏览器有整理工作要做,因此您的所有工作需要在 10 毫秒内完成。如果无法符合此预算,帧率将下降,并且内容会在屏幕上抖动。 此现象通常称为卡顿,会对用户体验产生负面影响。

假如你用 JavaScript 修改了 DOM,并触发样式修改,经历重排重绘最后画到屏幕上。如果这其中任意一项的执行时间过长,都会导致渲染这一帧的时间过长,平均帧率就会下降。假设这一帧花了 50 ms,那么此时的帧率为 1s / 50ms=20fps,页面看起来就像卡顿了一样。
对于一些长时间运行的 JavaScript,我们可以使用定时器进行切分,延迟执行。
for (let i=0, len=arry.length; i < len; i++){
process(arry[i])
}
假设上面的循环结构由于 process() 复杂度过高或数组元素太多,甚至两者都有,可以尝试一下切分。
const todo=arry.concat()
setTimeout(function(){
process(todo.shift())
if (todo.length){
setTimeout(arguments.callee, 25)
}else{
callback(arry)
}
}, 25)
从第 16 点我们可以知道,大多数设备屏幕刷新率为 60 次/秒,也就是说每一帧的平均时间为 16.66 毫秒。在使用 JavaScript 实现动画效果的时候,最好的情况就是每次代码都是在帧的开头开始执行。而保证 JavaScript 在帧开始时运行的唯一方式是使用 requestAnimationFrame。
/**
* If run as a requestAnimationFrame callback, this
* will be run at the start of the frame.
*/
function updateScreen(time){
// Make visual updates here.
}
requestAnimationFrame(updateScreen);
如果采取 setTimeout 或 setInterval 来实现动画的话,回调函数将在帧中的某个时点运行,可能刚好在末尾,而这可能经常会使我们丢失帧,导致卡顿。
Web Worker 使用其他工作线程从而独立于主线程之外,它可以执行任务而不干扰用户界面。一个 worker 可以将消息发送到创建它的 JavaScript 代码, 通过将消息发送到该代码指定的事件处理程序(反之亦然)。
Web Worker 适用于那些处理纯数据,或者与浏览器 UI 无关的长时间运行脚本。
创建一个新的 worker 很简单,指定一个脚本的 URI 来执行 worker 线程(main.js):
var myWorker=new Worker('worker.js');
// 你可以通过postMessage() 方法和onmessage事件向worker发送消息。
first.onchange=function(){
myWorker.postMessage([first.value,second.value]);
console.log('Message posted to worker');
}
second.onchange=function(){
myWorker.postMessage([first.value,second.value]);
console.log('Message posted to worker');
}
在 worker 中接收到消息后,我们可以写一个事件处理函数代码作为响应(worker.js):
onmessage=function(e){
console.log('Message received from main script');
var workerResult='Result: ' + (e.data[0]* e.data[1]);
console.log('Posting message back to main script');
postMessage(workerResult);
}
onmessage处理函数在接收到消息后马上执行,代码中消息本身作为事件的data属性进行使用。这里我们简单的对这2个数字作乘法处理并再次使用postMessage()方法,将结果回传给主线程。
回到主线程,我们再次使用onmessage以响应worker回传的消息:
myWorker.onmessage=function(e){
result.textContent=e.data;
console.log('Message received from worker');
}
在这里我们获取消息事件的data,并且将它设置为result的textContent,所以用户可以直接看到运算的结果。
不过在worker内,不能直接操作DOM节点,也不能使用window对象的默认方法和属性。然而你可以使用大量window对象之下的东西,包括WebSockets,IndexedDB以及FireFox OS专用的Data Store API等数据存储机制。
JavaScript 中的数字都使用 IEEE-754 标准以 64 位格式存储。但是在位操作中,数字被转换为有符号的 32 位格式。即使需要转换,位操作也比其他数学运算和布尔操作快得多。
取模
由于偶数的最低位为 0,奇数为 1,所以取模运算可以用位操作来代替。
if (value % 2){
// 奇数
}else{
// 偶数
}
// 位操作
if (value & 1){
// 奇数
}else{
// 偶数
}
取整
~~10.12 // 10
~~10 // 10
~~'1.5' // 1
~~undefined // 0
~~null // 0
位掩码
const a=1
const b=2
const c=4
const options=a | b | c
通过定义这些选项,可以用按位与操作来判断 a/b/c 是否在 options 中。
// 选项 b 是否在选项中
if (b & options){
...
}
无论你的 JavaScript 代码如何优化,都比不上原生方法。因为原生方法是用低级语言写的(C/C++),并且被编译成机器码,成为浏览器的一部分。当原生方法可用时,尽量使用它们,特别是数学运算和 DOM 操作。
(1). 浏览器读取选择器,遵循的原则是从选择器的右边到左边读取。
看个示例
#block .text p{
color: red;
}
(2). CSS 选择器优先级
内联 > ID选择器 > 类选择器 > 标签选择器
根据以上两个信息可以得出结论。
最后要说一句,据我查找的资料所得,CSS 选择器没有优化的必要,因为最慢和慢快的选择器性能差别非常小。
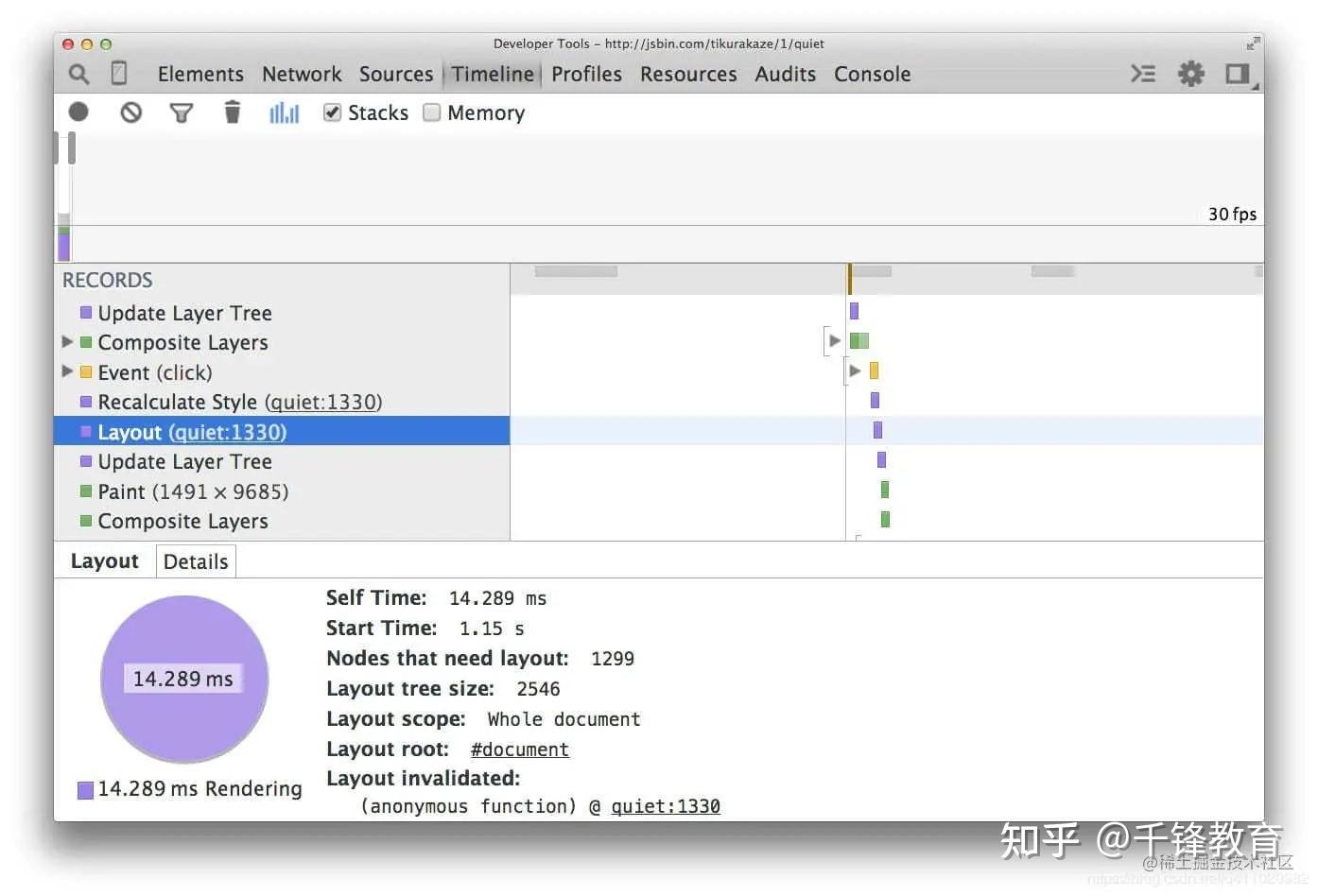
在早期的 CSS 布局方式中我们能对元素实行绝对定位、相对定位或浮动定位。而现在,我们有了新的布局方式 flexbox,它比起早期的布局方式来说有个优势,那就是性能比较好。
下面的截图显示了在 1300 个框上使用浮动的布局开销:
然后我们用 flexbox 来重现这个例子:
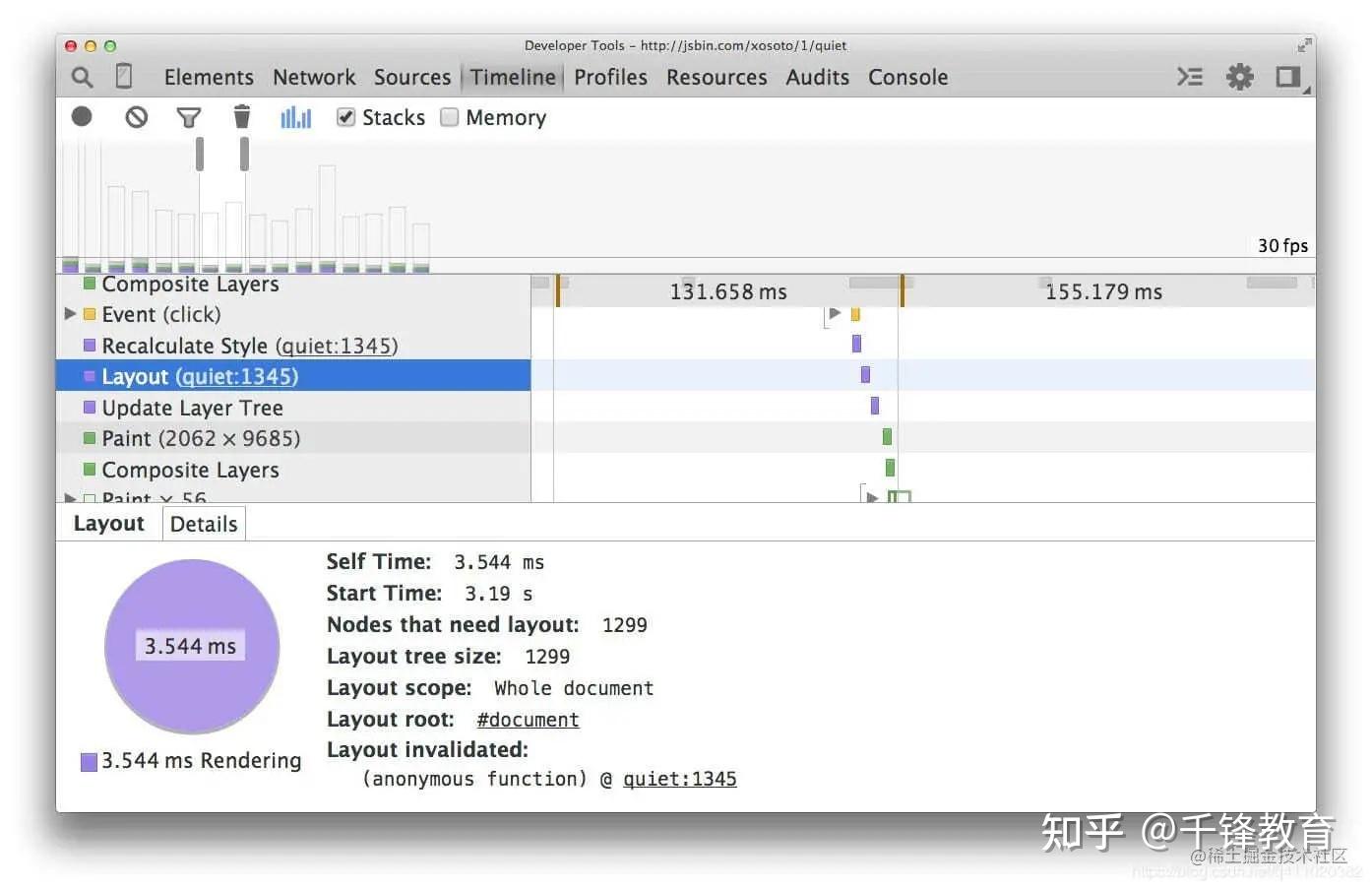
现在,对于相同数量的元素和相同的视觉外观,布局的时间要少得多(本例中为分别 3.5 毫秒和 14 毫秒)。
不过 flexbox 兼容性还是有点问题,不是所有浏览器都支持它,所以要谨慎使用。
各浏览器兼容性:
在 CSS 中,transforms 和 opacity 这两个属性更改不会触发重排与重绘,它们是可以由合成器(composite)单独处理的属性。

性能优化主要分为两类:
上述 23 条建议中,属于加载时优化的是前面 10 条建议,属于运行时优化的是后面 13 条建议。通常来说,没有必要 23 条性能优化规则都用上,根据网站用户群体来做针对性的调整是最好的,节省精力,节省时间。
在解决问题之前,得先找出问题,否则无从下手。所以在做性能优化之前,最好先调查一下网站的加载性能和运行性能。
一个网站加载性能如何主要看白屏时间和首屏时间。
将以下脚本放在 </head> 前面就能获取白屏时间。
<script>
new Date() - performance.timing.navigationStart
// 通过 domLoading 和 navigationStart 也可以
performance.timing.domLoading - performance.timing.navigationStart
</script>
在 window.onload 事件里执行 new Date() - performance.timing.navigationStart 即可获取首屏时间。
配合 chrome 的开发者工具,我们可以查看网站在运行时的性能。
打开网站,按 F12 选择 performance,点击左上角的灰色圆点,变成红色就代表开始记录了。这时可以模仿用户使用网站,在使用完毕后,点击 stop,然后你就能看到网站运行期间的性能报告。如果有红色的块,代表有掉帧的情况;如果是绿色,则代表 FPS 很好。performance 的具体使用方法请用搜索引擎搜索一下,毕竟篇幅有限。
通过检查加载和运行性能,相信你对网站性能已经有了大概了解。所以这时候要做的事情,就是使用上述 23 条建议尽情地去优化你的网站,加油!
来源:谭光志


