富达资讯

全国统一免费咨询电话
400-123-4567
传真:+86-123-4567
手机:138-0000-0000
Q Q:1234567890
E_mail:admin@youweb.com
地址:广东省广州市天河区88号
快速排序的4种优化
? ? ? ? ? 固定基准
? ? ? ? ? 随机基准
? ? ? ? ? 三数取中
快排算法是基于分治策略的排序算法,其基本思想是,对于输入的数组 a[low, high],按以下三个步骤进行排序。
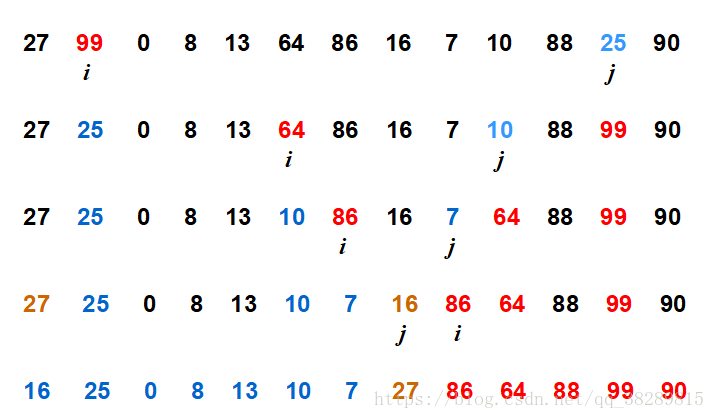
(1)分解:以 a[p] 为基准将 a[low: high] 划分为三段 a[low: p-1],a[p] 和 a[p+1: high],使得 a[low: p-1] 中任何一个元素小于等于 a[p],?而 a[p+1: high] 中任何一个元素大于等于 a[p]。
(2)递归求解:通过递归调用快速排序算法分别对 a[low: p-1] 和 a[p+1: high] 进行排序。
(3)合并:由于对 a[low: p-1] 和 a[p+1: high] 的排序是就地进行的,所以在 a[low: p-1] 和 a[p+1: high] 都已排好序后,不需要执行任何计算,a[low: high] 就已经排好序了。
快速排序的运行时间与划分是否对称有关。最坏情况下,每次划分过程产生两个区域分别包含n-1个元素和1个元素,其时间复杂度会达到O(n^2)。在最好的情况下,每次划分所取的基准都恰好是中值,即每次划分都产生两个大小为n/2的区域。此时,快排的时间复杂度为O(nlogn)。所以基准的选择对快排而言至关重要。快排中基准的选择方式有以下三种。
以下Partition()函数对数组进行划分时,以元素x = a[low]作为划分的基准。
快排过程一趟:
快排动图(网上找的动图,其中有一个基准为 6?的标识错误。虽然基准选择方法不一样,但排序过程还是一样的):
如果数组元素是随机的,划分过程不产生极端情况,那么程序的运行时间不会有太大的波动。如果数组元素已经基本有序时,此时的划分就容易产生最坏的情况,即快速排序变成冒泡排序,时间复杂度为O(n^2)。
例如:序列[1][2][3][5][4][6]以固定基准进行快排时。
第一趟:[1][2][3][5][4][6]
第二趟:[1][2][3][5][4][6]
第三趟:[1][2][3][5][4][6]
第四趟:[1][2][3][4][5][6]
程序中要用的函数:(1)C++可以使用以下方法产生随机数,而单纯的使用rand()%M产生的是伪随机数。
(2)方法一:获得程序片段运行的时间:
方法二:获得程序片段运行的时间:
例如:
完整代码如下:
p.s:(1)在Codeblocks下处理升序数组时,元素最好设置少一点。设置的太大可能会出现下图提示:
(2)重复数组中的元素值只有两个。
(3)随机数组(较多重复元素)的设置是:a[i] = rand()%(M/100);。
数据如下:
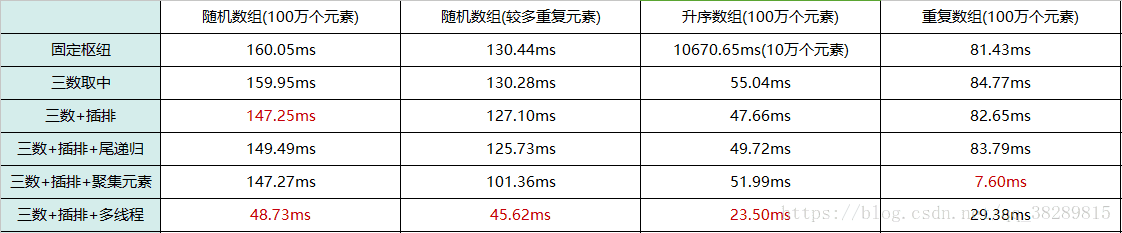
固定基准对升序数组的分割极其糟糕,排序时间特别长,所以只设置了10万个元素。
在待排数组有序或基本有序的情况下,选择使用固定基准影响快排的效率。为了解决数组基本有序的问题,可以采用随机基准的方式来化解这一问题。算法如下:
此时,原来Partition()函数里的T x = a[low];相应的改为T x = Random(a, low, high);
虽然使用随机基准能解决待排数组基本有序的情况,但是由于这种随机性的存在,对其他情况的数组也会有影响(若数组元素是随机的,使用固定基准常常优于随机基准)。随机数算法(Sherwood算法)能有效的减少升序数组排序所用的时间,数组元素越多,随机数算法的效果越好。可以试想,上述升序数组中有10万个元素而且各不相同,那么在第一次划分时,基准选的最差的概率就是十万分之一。当然,选择最优基准的概率也是十万分之一,随机数算法随机选择一个元素作为划分基准,算法的平均性能较好,从而避免了最坏情况的多次发生。许多算法书中都有介绍随机数算法,因为算法对程序的优化程度和下面所讲的三数取中方法很接近,所以我只记录了一种方法的运行时间。
由于随机基准选取的随机性,使得它并不能很好的适用于所有情况(即使是同一个数组,多次运行的时间也大有不同)。目前,比较好的方法是使用三数取中选取基准。它的思想是:选取数组开头,中间和结尾的元素,通过比较,选择中间的值作为快排的基准。其实可以将这个数字扩展到更大(例如5数取中,7数取中等)。这种方式能很好的解决待排数组基本有序的情况,而且选取的基准没有随机性。
例如:序列[1][1][6][5][4][7][7],三个元素分别是[1]、[5]、[7],此时选择[5]作为基准。
第一趟:[1][1][4][5][6][7][7]
三数取中算法如下:
同理,Partition()函数里的T x = a[low];相应的改为T x =?NumberOfThree(a, low, high);
数据如下:
三数取中(随机数算法效果相同)在处理升序数组时有质的飞越,而且处理的还是100万个元素。
当快排达到一定深度后,划分的区间很小时,再使用快排的效率不高。当待排序列的长度达到一定数值后,可以使用插入排序。由《数据结构与算法分析》(Mark Allen Weiness所著)可知,当待排序列长度为5~20之间,此时使用插入排序能避免一些有害的退化情形。
完整代码如下:
数据如下:
如上所述,在划分到很小的区间时,里面的元素已经基本有序了,再使用快排,效率就不高了。所以,在结合插入排序后,程序的执行效率有所提高。
快排算法和大多数分治排序算法一样,都有两次递归调用。但是快排与归并排序不同,归并的递归则在函数一开始, 快排的递归在函数尾部,这就使得快排代码可以实施尾递归优化。使用尾递归优化后,可以缩减堆栈的深度,由原来的O(n)缩减为O(logn)。
尾递归概念:
如果一个函数中所有递归形式的调用都出现在函数的末尾,当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码。
尾递归原理:
当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。
代码如下:
示例中的函数是尾递归的,因为对facttail的单次递归调用是函数返回前最后执行的一条语句。在facttail中碰巧最后一条语句也是对facttail的调用,但这并不是必需的。换句话说,在递归调用之后还可以有其他的语句执行,只是它们只能在递归调用没有执行时才可以执行。尾递归是极其重要的,不用尾递归,函数的堆栈耗用难以估量,需要保存很多中间函数的堆栈。比如f(n, sum) = f(n-1) + value(n) + sum; 会保存n个函数调用堆栈,而使用尾递归f(n, sum) = f(n-1, sum+value(n)); 这样则只保留后一个函数堆栈即可,之前的可优化删去。
代码当n=5时,线性递归的递归过程如下:
而尾递归的递归过程如下:
关于尾递归及快排尾递归优化可以看这篇博文:尾递归及快排尾递归优化?,其中包含了上述阶乘问题、快排尾递归优化和Gdb调试等内容。
在Codeblocks里运行快排代码处理升序数组,一个进行尾递归优化,而另一个不变。没有使用尾递归的代码处理4万个数组元素时,由于超过了栈的深度,程序会异常结束。而使用了尾递归的代码,就算处理10万个数组元素,也不会出现异常(结合三数取中,可以处理100万个数组元素)。
2018年10月2日补充:结合我的另一篇博文《内存四区》,对上述问题有更全面的认识。
快排尾递归代码如下:
第一次递归以后,变量low就没有用处了, 也就是说第二次递归可以用迭代控制结构代替。快排尾递归过程如下,纵向是递归,横向是迭代。
数据如下:
对递归的优化,主要是为了减少栈深度。在处理随机数组时,(三数取中+插排+尾递归)的组合并不一定比(三数取中+插排)的效率高。
聚集元素的思想:在一次分割结束后,将与本次基准相等的元素聚集在一起,再分割时,不再对聚集过的元素进行分割。具体过程有两步,①在划分过程中将与基准值相等的元素放入数组两端,②划分结束后,再将两端的元素移到基准值周围。
普通过程例如:[7][2][7][1][7][4][7][6][3][8] 由三数取中可得基准为[7]
第一趟:[7] [2] [3] [1] [6] [4]?[7]?[7] [7] [8]
第二趟:[1] [2] [3]?[4]?[6] [7] [7] [7] [7] [8]
第三趟:[1]?[2]?[3] [4] [6] [7] [7] [7] [7] [8]
第四趟:[1] [2] [3] [4] [6] [7] [7]?[7]?[7] [8]
聚集相同元素:
第一步:[7] [7] [7] [1] [2] [4]?[3]?[6] [7] [8]
第二步:[6] [3] [4] [1] [2] [7]?[7]?[7] [7] [8]
接下来是对[6] [3] [4] [1] [2] 和 [8]进行快排。(具体过程可以按照以下代码走一遍)
聚集元素第一步:
聚集元素第二步:
下一次就是对[6] [3] [4] [1] [2] 进行快排。当划分区间达到插入排序的要求时,就使用插入排序完成后续工作,所以进入插入排序那一段代码是停止继续递归的标志。
数据如下:
从上表中可以看到,通过对快排聚集元素的优化,在处理数组中的重复元素时有很大的提升。而对于升序数组而言,因为其本身就是有序的,而且没有重复元素,所以结果没有(三数取中+插排)效率高。
分治法的基本思想是将一个规模为n的问题分解为k个规模较小的子问题,这些子问题互相独立且与原问题相同。求解这些子问题,然后将各子问题的解合并,从而得到的原问题的解。由此,在处理快排的时候,可以使用多线程提高排序的效率。
要使用的函数:
(1)pthread_create
创建一个线程的函数是pthread_create。其定义如下:
第一个参数是一个整数类型,它表示的是资源描述符,实际上,Linux上几乎所有的资源标识符都是一个整型数。第二个attr参数用于设置新线程的属性。给它传递NULL表示使用默认线程属性。start_routine和arg参数分别指定新线程将运行的函数及其参数。
pthread_create()成功时返回0,失败时返回错误码。
(2)pthread_barrier_init
多线程编程时,可以使用这个函数来等待其它线程结束,例如:主线程创建一些线程,这些线程去完成一些工作,而主线程需要去等待这些线程结束(pthread_join也能实现一种屏障)。可以把屏障理解为:为了协同线程之间的工作而使得某一具体线程进入等待状态的一种机制。其原型:
函数执行成功返回 0,执行失败则返回一个错误号,我们可以通过该错误号获取相关的错误信息。
第一个参数:一个指向pthread_barrier_t 类型的指针,我们必须要指出的是pthread_barrier_init函数不会给指针分配相关内存空间,因此我们传入的指针必须为一个pthread_barrier_t 变量。
第二个参数:用于指定屏障的细节参数,我们这里可以暂且不去管它,如果我们传入NULL,那么系统将按照默认情况处理。
第三个参数:设计屏障等待的最大线程数目。
(3)pthread_barrier_wait
当一个线程需要等待其它多个线程结束时,调用该函数。
原型:
函数执行成功返回 0,执行失败则返回一个错误码,我们可以通过该错误码获取相关的错误信息。
函数参数:指向pthread_barrier_t 变量的指针。
注意:使用barrier这个屏障,无法获取线程的结束状态。若想要获取相关线程结束状态,则需要调用pthread_join函数。
代码如下:
上传完这段代码,同学告诉我说,这段代码在Linux和Codeblocks里运行的时间不一样(本篇博文的数据都是在Codeblocks上测得的)。然后我立马就测试了一下,发现这之间存在误差,初步猜测是由于编译器引起的。由于我不是双系统,是在虚拟机上运行的Linux系统,这可能是造成误差原因之一(个人认为可以忽略误差,虽然每组数据在不同环境下平均运行时间有差距,但其整体优化的方向是不变的)。
数据如下:
从上表可以看出,结合了多线程的快排(三数+插排+多线程)在处理前三种数组时都有明显的提升。重复数组处理时间增加的原因是:聚集元素在处理重复数组时的表现已经很好了,因为在多线程的组合中,各个线程排完序后要合并,所以增加了(三数+插排+多线程)这一组合的排序时间。因为时间原因,以上的数据,是运行相应代码10次所取得平均值。如果想要得到更精确的数据,需要大量的运行上述代码(即使存在一些不稳定的数据,也不会影响到代码优化的方向)。PS.以上程序运行时间还与个人所使用的电脑配置有关。
参考:
快速排序 优化 详细分析_HermanLiu的博客-CSDN博客